과적합에 대해 알기 전에 거슬러 올라가서 머신러닝에 대해 다시 알아보겠습니다.
1. 머신 러닝 (Machine learning)
머신러닝, 지도학습이라고 하고 학습 대상이 되는 데이터에 정답(label)을 붙여 학습시키고, 모델을 얻어서 완전히 새로운 데이터에 모델을 사용해서 답을 얻고자 하는 것을 나타냅니다.
머신러닝의 일반적인 절차는 다음과 같습니다.
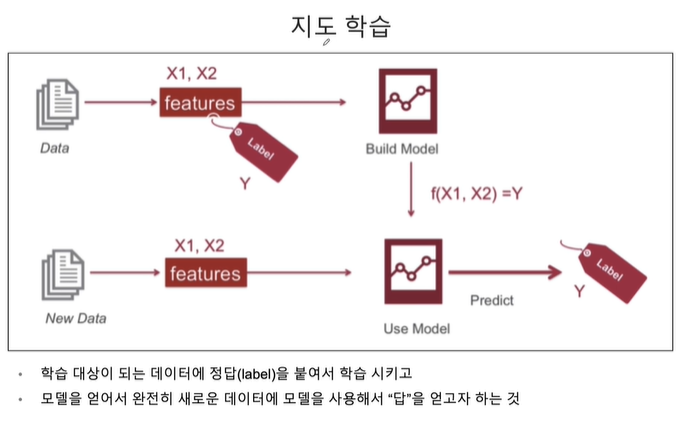
윗 줄은 학습, 아랫 줄은 추론이라고 부릅니다.
2. Tree model visualization
머신 러닝을 통해 얻은 Tree가 어떻게 생겼는지 한번 봐야겠죠? scikit learn의 tree 모듈의 plot_tree()라는 함수를 사용할겁니다.
from sklearn.tree import plot_tree
plt.figure(figsize=(12,6))
plot_tree(iris_tree)
plot_tree는 decision tree의 구조를 보여줍니다. 위 코드는 학습이 완료된 모델이 저장된 변수가 iris_tree이고, iris_tree가 어떻게 생겼는지 보여주라는 함수입니다.
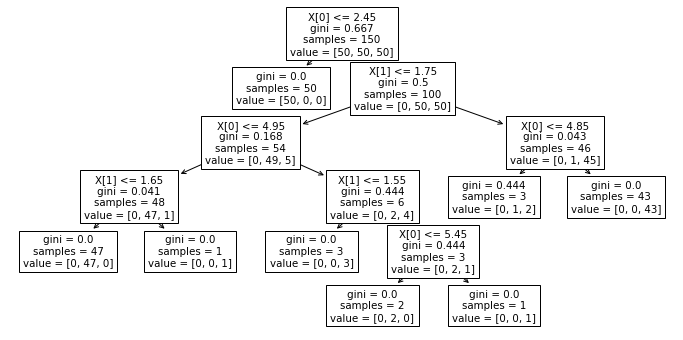
생각보다 복잡한 위 그림이 모델 구조입니다. X[0]=petal length를 나타내는 것, X[1]이 petal width를 나타내는 것이었죠? iris.data[:,2:]로 만든 iris_tree니까요.
두번째 줄 왼쪽의 gini는 gini계수를 뜻하고, 다음 게시글에서 다루도록 하겠습니다. 우선 gini 계수는 작을수록 무질서도가 낮은 것으로, gini=0인건 모두 다 setosa임을 맞췄다는 것을 의미합니다.
그런데 세번째줄 첫번째 박스를 보면, vergicolor에서 5개가 들어왔는데 이 5개가 틀린거라서 조건을 더 달아버렸습니다.
이 모델이 99.3%였던 모델입니다. 그런데 저 5개가 이렇게까지 맞출 데이터 인지 알 수는 없습니다.
우선 scatter 그래프에서 어떻게 선이 나뉘었는지 그림을 통해 알아보겠습니다.
mlxtend라는 모듈을 사용할 건데요, sklearn에 없는 몇몇 유용한 기능을 가지고 있습니다.
바로 "결정 경계"를 확인할 수 있습니다.
mlxtend를 통해 iris 품종을 분류하는 결정나무 모델이 어떻게 분류되었는지 확인해보겠습니다.
!pip install mlxtend
from mlxtend.plotting import plot_decision_regions
plt.figure(figsize=(14,8))
plot_decision_regions(X=iris.data[:,2:], y=iris.target, clf=iris_tree, legend=2)
clf 는 classification으로 iris_tree에 학습되어 저장되어 있었습니다. legend는 범례로, 2 위치에 찍어달라고 하겠습니다.
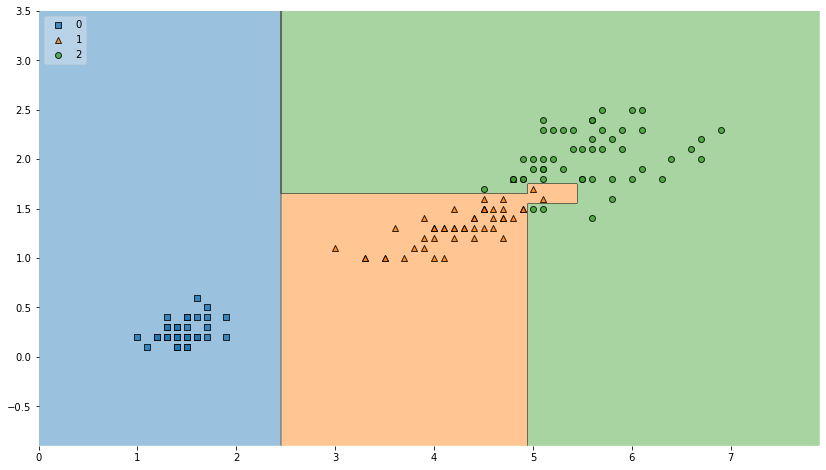
이렇게 mlxtend를 통해 결정 경계를 확인할 수 있었습니다.
그런데 중앙의 경계면이 복잡한 부분이 있는데 이 부분에 대해서 우리는 어떻게 생각해야 할까요?
이 부분이 저렇게 복잡하게 되어있기 때문에 accuracy가 99.3%가 나온것입니다.
즉 이 99.3%를 믿으면 안되는 것입니다. 이 150개 데이터가 이 세상에 있는 모든 setosa, vergicolor, virginica 모든 iris를 대변할 수 없기 때문에, 이 과적합을 신뢰할 수 없습니다.
심지어, 알고보니 저 데이터들이 돌연변이 같은 데이터라면?
위 fitting이 과적합(over fitting) 이었다면?
fisher 아저씨가 이상한 데이터를 가져왔다면?
3. 과적합 (Over fitting)
저 결과가 일반화 할 수 있다는 확신이 없기 때문에 복잡한 경계면은 결국 모델의 성능을 나쁘게 만든다고 볼 수 있습니다.
내가 가진 데이터'에만' 적합하면 안된다.
따라서 우리는 머신러닝을 할 때 150개 밖에 없는 데이터지만 그 중에 일부를 뽑아서 훈련을 시키고 나머지를 테스트용으로 씁니다.
여기에서 더 나아가면, 훈련(Training), 검증(Validation), 테스트(Testing) 데이터 세개로 나눌 수 있습니다.
참고로 이 모든건 과적합으로 인해 발생합니다...
'머신러닝' 카테고리의 다른 글
| 타이타닉 생존자 예측_생존율 관련 요소 (0) | 2024.02.23 |
|---|---|
| Decision Tree를 사용한 Iris 분류_데이터 나누기 (0) | 2024.02.23 |
| Entropy와 Gini 계수 (0) | 2024.02.21 |
| Decision Tree를 사용한 Iris 분류_데이터 학습 및 예측 (0) | 2024.02.21 |
| Decision Tree를 사용한 Iris 분류_데이터 관찰 (1) | 2024.02.19 |



