이전 게시글에서 알려드린 대로, 우리는 train 데이터와 test 데이터를 나누어야 합니다.
데이터를 나누는 방법을 사용하기 위해 처음부터 데이터를 불러오겠습니다.
1. 데이터 불러오기
from sklearn.datasets import load_iris
import pandas as pd
iris = load_iris()
iris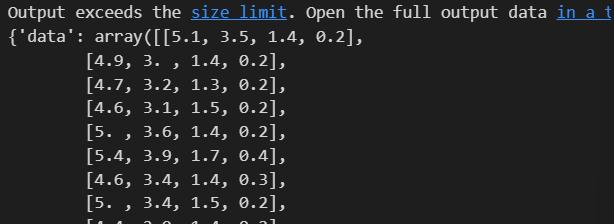
2. 데이터 나누기
데이터를 잘 나눠주는 아이가 scikit learn에서 제공됩니다. sklearn의 model_selection 모듈에 train_test_split() 함수입니다.
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(feature = iris.data[:,2:],
labels = iris.target,
test_size = 0.2, #훈련용 80%, test 20% 나누겠다는 뜻
random_state=13)
여기서 feature와 label은 이제 아실거고, test_size와 random_state가 궁금하실 겁니다.
test_size는 train 데이터와 test 데이터를 몇 대 몇으로 나눌 지 정해주는 옵션입니다. test_size가 0.2이니, 훈련용이 80%, 학습용이 20%라는 뜻입니다.
random_state는 python에서 제공하는 random성을 똑같이 가져갈 수 있게 해주는 것으로 원래 데이터를 랜덤하게 가져오지만, 랜덤하게 가져오는 것조차 강의와 똑같이 가져오게 만들기 위해서 옵션을 줬습니다.
이제 하나하나 살펴보겠습니다.
X_train
데이터가 들어간 것 같긴 한데...
몇 개가 들어있는지 확인해봐야 겠죠? 각 class별 분포부터 확인해봐야합니다.
X_train.shape, X_test.shape

shape을 확인해보면 120개와 30개로 8:2로 나뉜 것을 확인할 수 있습니다.
그런데 8:2로 나뉘었다고 다 해결된 것이 아닙니다. 만약에 3 종중에 한 종이 쏠려서 들어갔으면 어떻게 합니까? 따라서 이 과정을 할 때 unique 검사를 꼭 해야합니다.
다시말해, 120개 안에 setosa, vergicolor, virginica가 얼마나 들어있는지 확인해야 하기 때문이다.
우선, 지금 이 데이터가 pandas 데이터가 아니기 때문에 numpy에서 확인해야합니다.
import numpy as np
np.unique(y_test)
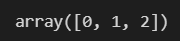
어라, 이렇게 달랑 구성요소 0, 1, 2가 있다고만 알려줍니다. 몇개 있는지 알고 싶으면 return_counts라는 옵션을 주면 됩니다.
np.unique(y_test, return_counts=True)
9, 8, 13개로 나뉜것을 알 수 있습니다. 골고루 있을수록 더 좋겠는데요,
따라서 0, 1, 2를 각각 8:2로 나누어주면 어떨까요? 다행히 이 옵션은 train_test_split()의 stratify에 있습니다.
X_train, X_test, y_train, y_test = train_test_split(feature=iris_data[:,2:],
labels=iris.target,
test_size=0.2,
stratify=iris.target, #stratify에 laels(0,1,2로 된 값)을 주면 0,1,2에서 각각 8:2로 나뉘게 됩니다.
random_state=13)
stratify에 labels 즉, 0,1,2에서 각각 8:2로 나뉘게해주는 옵션을 주었습니다.
다시 개수를 확인해보겠습니다.
np.unique(y_test, return_counts=True)
이제 각각 10개 10개 10개로 나뉜것을 확인할 수 있습니다.
방금 전처럼 다시 train 데이터만 대상으로 결정나무 모델을 만들어보겠습니다.
from sklearn.tree import DecisionTreeClassifier
iris_tree = DecisionTreeClassifier(max_depth=2, random_state=13)
iris_tree.fit(X_train, y_train) #train 데이터로 fit(학습) 시킨다는 뜻
모델을 단순화 시키기 위해 max_depth를 조정하겠습니다.
from sklearn.tree import plot_tree
import matplotlib.pyplot as plt
plt.figure(figsize=(12,6))
plot_tree(iris_tree)

40개씩 균형있게 가져왔고 vergicolor와 virginica에서 오류가 몇개 있긴합니다. 그럼 이제 accuracy를 확인해보겠습니다.
from sklearn.metrics import accuracy_score
y_pred_tr = iris_tree.predict(iris.data[:, 2:])
accuracy_score(iris.target, y_pred_tr)
과적합이 있던 99.3에서 95.3으로 줄어들었습니다.
3. 모델 결정경계 확인
mlxtend로 모델 결정경계를 확인해보겠습니다.
from mlxtend.plotting import plot_decision_regions
plt.figure(figsize=(12,6))
plot_decision_regions(X=X_train, y=y_train, clf=iris_tree, legend=2)
plt.show()

더 틀렸지만 복잡하지 않고 깔끔합니다. max depth=2일때기 때문이죠.
이제 소중한 test 데이터에서 test를 해 볼 시간입니다.
y_pred_test = iris_tree.predict(X_test) #학습을 완료한 tree 데이터에게 예측하라고 명령한다.
accuracy_score(y_test, y_pred_test)
y_pred_test는 예측한 값이고, 적합도를 확인하는 것이 accuracy_score입니다.
참고로 전문가들은 아시겠지만, test 데이터가 더 수치가 높을리는 없고, 지금 iris data라서 이런 결과가 나온 것입니다.
이것으로 과적합은 안일어났구나 라는것을 확인할 수 있겠습니다.
만약 회사에서 상사가 과적합이 아닌지 어떻게 아니?라는 물음을 한다면 두 가지 답변을 할 수 있겠습니다.
1. 데이터를 더주세요.
2. train_test_split() 함수와 stratify를 통해 모든 데이터를 8:2로 나누어 확인해봤습니다.
라고얘기할 수 있겠습니다.
4. 테스트 데이터 시각화
테스트 데이터만 따로 시각화해서 볼 수도 있습니다.
scatter_highlight_kwargs 옵션을 사용하면 됩니다. ( kwargs : keyword arguments의 약자 )
scatter_highlight_kwargs = {'s':150, 'label':'Test data', 'alpha':0.9}
#marker의 특성이다. size를 150으로 주고, label을 지정하고 투명도를 0.9로 조금 주라고 명령했습니다.
scatter_kwargs = {'s':120, 'edgecolor': None, 'alpha':0.9}
plt.figure(figsize=(12,6))
plot_decision_regions(X=feature,
y=labels,
X_highlight=X_test, #test된 친구들을 highlight 시켜줌
clf=iris_tree,
legend=2,
scatter_highlight_kwargs=scatter_highlight_kwargs, #size를 키우고 test data라고 암시
scatter_kwargs=scatter_kwargs, #edge color를 없앰
contourf_kwargs={'alpha':0.2} #각 종에 따른 배경색을 옅게함
)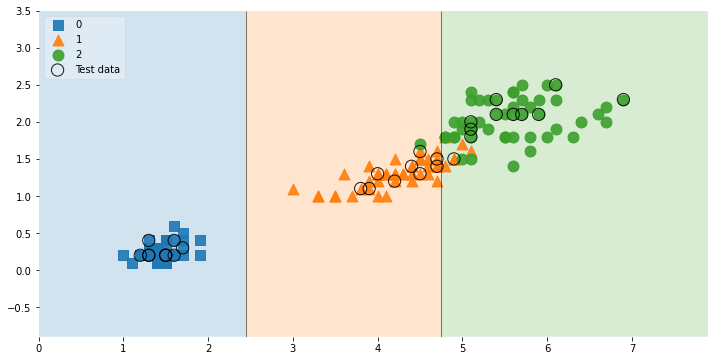
각각의 종에서 어떤것이 test 데이터로 선정되었는지 보여주는 그림입니다.
5. Iris 데이터 통째로 머신러닝
5-1. 데이터 불러오고 데이터 확인 후 split후 Tree 만들고 fit(학습)하기
이제 iris.data[:,2:]가 아닌, iris.data로 feature를 모두 포함해서 4개로 잡고 다시 진행해보겠습니다.(두근)
features = iris.data
labels = iris.target
X_train, X_test, y_train, y_test = train_test_split(features, labels,
test_size=0.2,
stratify=labels,
random_state=13)
iris_tree = DecisionTreeClassifier(max_depth=2, random_state=13)
iris_tree.fit(X_train, y_train)
plot_tree(iris_tree)
위 그림을 확인해보면 X[2], X[3]을 썼다는건 petal 특성만 썼다는 뜻이군요, 저희와 수작업으로 할 때와 같은 방식을 택한 것 같습니다..
우리가 모델을 쓰는 이유는 학습을 통해 얻은 모델을 가지고 새로운 데이터로 예측 결과를 얻어내려고 하는 것(추론 적용)이죠.
5-2. predict(예측)하기
그럼 이제 내가 길가다가 iris를 주웠고, 이를 tree 모델을 통해 어떤 종인지 확인할 수 있어야 합니다.
길가다 주운 Iris 데이터를 아무거나 잡아보겠습니다.
test_data = [[4.3, 2., 1.2, 1.]] #길 가다 주운 iris
iris_tree.predict(test_data) #tree 모델을 통해 예측해보자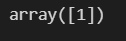
결과에서 나온 array 1이면 versicolor를 뜻합니다. (0,1,2 순서였습니다)
그런데 여기서 잠시, test_data가 [[]]로 괄호가 두개인 이유는 shape을 보면 알 수 있습니다.
np.array(test_data).shape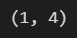
(1,4)가 나옵니다. 그런데 list를 하나로만 잡으면 어떻게 될까요?
test_data = [4.3, 2., 1.2, 1.]
np.array(test_data).shape
(4,)라고만 나옵니다. 행렬을 더하거나 빼려면 즉 행렬의 연산이 이루어지려면, 행렬의 크기가 맞아떨어져야합니다.
다시말해 왼쪽 오른쪽의 행의 수가 같아야 하는데 (4,)와 같은 경우 연산이 이루어질 수가 없습니다. 따라서 연산이 이루어질 수 있도록 [[]] shape으로 나타내야 합니다.
네... 다시 test_data를 돌려놓겠습니다.
test_data = [[4.3, 2., 1.2, 1.]] #길 가다 주운 iris
iris_tree.predict(test_data) #tree 모델을 통해 예측해보자
이를 통해 vergicolor임을 확인했죠, 그런데 여기서 vergicolor일 확률 및 각 종일 확률을 확인해보는 방법도 있습니다.
predict_proba()함수를 쓰면 됩니다.
iris_tree.predict_proba(test_data)
setosa일 확률 0, vergicolor일 확률 97.2%, virginica일 확률 2.7%입니다.
그런데, target_name을 같이 표시할 순 없을까요?
iris_tree.predict_proba(test_data)의 결과가 array[1]이니까 array[1]에 해당하는 target_names를 보려면 이렇게 하면 됩니다.
iris.target_names
의 결과가

였죠, 감이 오시나요?
iris.target_names[iris_tree.predict(test_data)]
이렇게 하시면 됩니다.
이제는 모델을 결정하는데 필요한 중요 feature를 아는 방법입니다.
feature_importances() 함수를 쓰면 됩니다.
iris_tree.feature_importances_
petal쪽 데이터만 써서 결과를 알 수 있다고 합니다.
혹시 max_depth가 낮아서 그런걸까 싶어 max_depth를 5로 더 늘려서 정확도를 더 높이면 importances가 어떻게 변하는지 한번 보겠습니다.
iris_tree = DecisionTreeClassifier(max_depth=5, random_state=13)
iris_tree.fit(X_train, y_train)
iris_tree.feature_importances_
sepal쪽 데이터도 같이 볼 수도 있다는걸 확인했습니다.
이번에는 iris의 feature_names와 tree 모델의 feature_importances_를 zipping 시키면 feature에 연결된 값을 확인할 수 있습니다.
iris_clf_model = dict(zip(iris.feature_names, iris_tree.feature_importances_))
iris_clf_model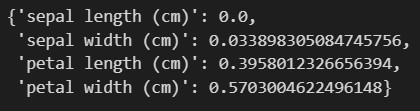
위와 같은 기술을 zipping과 unpacking이라고 합니다.
결과를 보여주는데 있어서 잔기술인 zipping과 unpacking에 대해 다음 게시글에서 알아보겠습니다.
5-3. accuracy(정확도) 확인하기
강의에서 다루지는 않았지만 마지막으로 정확도를 확인하면 끝입니다.
'머신러닝' 카테고리의 다른 글
| 타이타닉 생존자 예측_머신러닝 (0) | 2024.02.26 |
|---|---|
| 타이타닉 생존자 예측_생존율 관련 요소 (0) | 2024.02.23 |
| Decision Tree를 사용한 Iris 분류_과적합 (0) | 2024.02.22 |
| Entropy와 Gini 계수 (0) | 2024.02.21 |
| Decision Tree를 사용한 Iris 분류_데이터 학습 및 예측 (0) | 2024.02.21 |



