이전 시간에는 scikit learn의 dataset 모듈에 있는 load_iris 데이터에 대해 알아보고, Decision Tree 알고리즘을 통해 분류하는 방식을 수작업으로 진행해봤습니다. 그럼 이번 시간에는 직접 scikit learn에서 Decision Tree 알고리즘을 사용해보려고 합니다.
1.구분하기 쉬운 그래프로 시각화하기
pair plot을 통해 petal length와 petal width로 구분하는 것이 3종을 구분하기 쉽다는걸 확인했으니, scatter로 그래프를 그려보겠습니다.
plt.figure(figsize=(12,6))
sns.scatterplot(x='petal length (cm)', y='petal width (cm)',
data=iris_pd, hue='species', palette='Set2')
seaborn의 scatter plot 그래프를 그릴 때 주의할 점은 hue를 'species'로 줘야 각 종에 따라 색을 구분해서 보여줍니다.
x, y값에 오류가 나지 않게 data frame으로 봤을 때 feature 이름을 그대로 복사해서 넣어주는 것이 좋습니다.
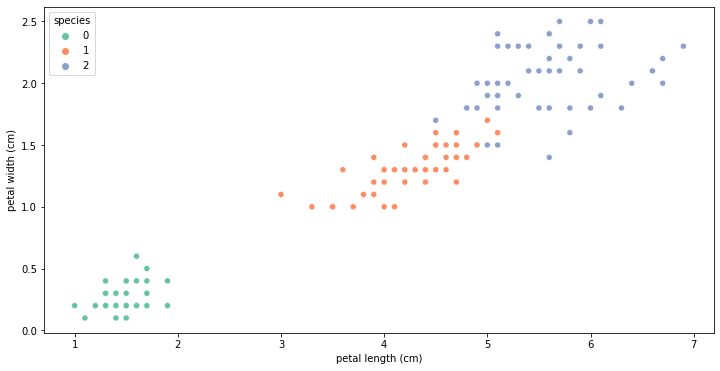
그래프를 보면, 첫번째 setosa는 구분이 너무 잘 되는데 vergicolor와 virginica를 구분하는 두번째 선을 어떻게 잘 그을것인가가 문제입니다. 우리는 공부중이니, 결과를 보기보다 이것저것 코드를 짜보는 것이 좋습니다. 이후 데이터 학습을 위해 vergicolor와 virginica 두 개의 데이터에 집중해보겠습니다.
1-1. vergicolor와 virginica 데이터만 불러오기
iris_pd['species'] != 0
위 코드는 값이 species가 0이냐 아니냐로 True와 False로 나뉘는 일종의 mask가 될 수 있습니다.
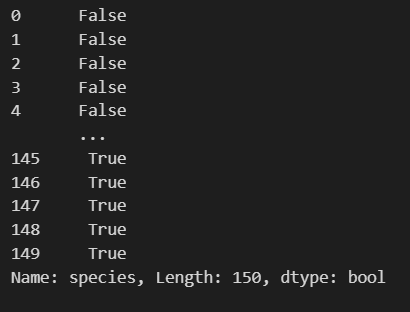
다음과 같이 결과가 나오죠? 이를 iris_pd에 씌우면 True만 반환해줍니다.
iris_pd[iris_pd['species']!=0]
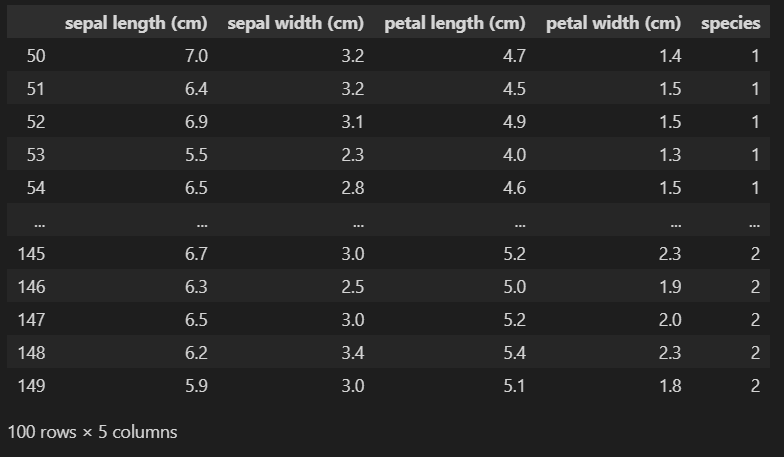
50부터 149까지 총 100개의, species가 1, 2인 데이터만 나오는 것을 확인할 수 있습니다.
이를 iris_12 변수에 넣고 info() 함수를 통해 데이터를 확인해보겠습니다.
iris_12 = iris_pd[iris_pd['species']!=0]
iris_12.info()
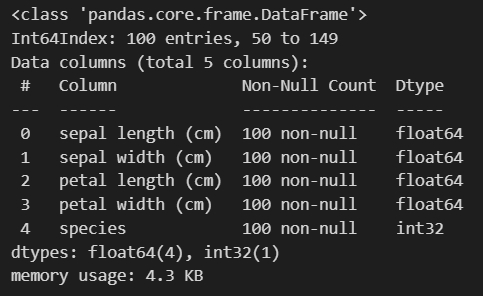
이 결과에서 확인할 것은 index가 50부터 149인 것, feature 개수가 4개고, species는 class의 역할을 하는 것, 각 데이터가 100개씩 있다는 것을 확인하면 됩니다.
1-2. 시각화 및 split criterion
plt.figure(figsize=(12,6))
sns.scatterplot(x='petal length (cm)', y='petal width (cm)',
data=iris_12, hue='species', palette='Set2');

이 데이터가 세상 모든 iris라면 위의 데이터만으로 경계를 갈라버리면 됩니다. 그러가 그게 아니기 때문에 경계를 나누기 애매한 상황입니다. 지금은 우선 vergicolor와 virginica를 나누는 경계선이 오직 직선이어야 한다고 가정하고 생각해보겠습니다. *사선도 안되고 수평/수직 선이어야 합니다.
그러면 몇가지 4-5가지 틀린 데이터들이 발생하게 됩니다. 경계선이 어디에 있어야 최고일까요..?

Decision Tree에서는 이렇게 선으로 나누는 것을 분할기준(split criterion)이라고 표현합니다.
2. Scikit learn의 Decision Tree 사용하기
2-1. Scikit learn
2007년 구글 썸머코드에서 처음 구현했고, 현재 파이썬에서 가장 유명한 기계학습 오픈소스 라이브러리입니다.
2-2. Decision Tree를 통한 학습
from sklearn.tree import DecisionTreeClassifier
iris_tree = DecisionTreeClassifier()
iris_tree
이렇게하면 Decision Tree 학습이 끝난겁니다. 간단하죠? iris_tree에 iris 데이터의 tree 모델이 들어있습니다.
이제 petal length, width가 영향력이 높았으므로, 두개만 따로 가져와보겠습니다.
iris.data[:,2:] #모든 행의 2번 이후만 가져오겠다
이렇게하면 모든 행의 2번째 행 이후만 가져올 수 있습니다.

이제 이 데이터를 iris_tree에 fit 명령을 줘서 학습시킬겁니다
- fit() : 내가 데이터를 줄테니 니가 좀 학습해봐라 라는 뜻이라고 강의에서 언급하네요...
근데 fit은 그냥 학습하지 않고, 정답을 알려줘야 학습할 수 있습니다. 따라서, iris.target()을 뒤에 꼭 넣어줘야합니다.
코드로 보면 이렇게 되는거죠. iris_tree.fit('데이터', '정답')
iris_tree.fit(iris.data[:,2:], iris.target)
고작 세줄이지만 내가 데이터를 줄게, 정답을 줄게, 니가 학습을 할래?가 다 담겨있는 문장입니다.
이제 성능을 확인해보겠습니다.
2-3. Decision Tree를 통한 예측
현재 iris_tree는 학습이 완료된 상태입니다. 학습이 완료된 iris_tree에게 예측(predict)해보라고 시켜보는겁니다.
이 데이터 (iris.data[:,2:]) 를 줄테니, 정답은 주지 않을테니 니가 결과를 확인해봐라고 합니다.
y_pred_tr = iris_tree.predict(iris.data[:,2:])
y_pred_tr
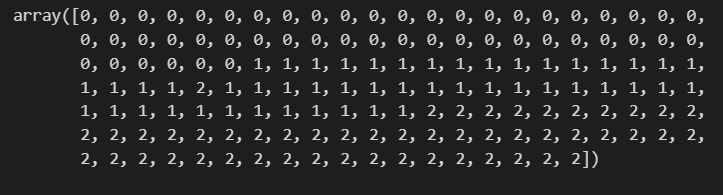
학습한 결과를 통해 iris의 모든 데이터로 결과를 예측해 보았습니다. setosa는 거의 다 맞는 것 같은데... 아쉽게도 vergicolor에서 오류가 있어 보입니다. 답과 비교해보겠습니다.
iris.target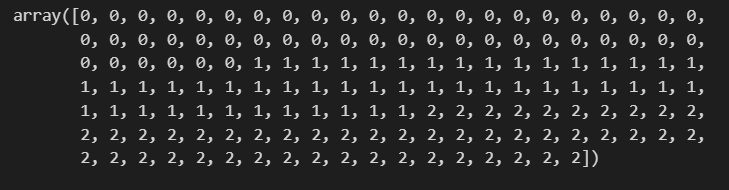
virginica 첫번째 데이터도 오류가 있었네요... 역시 눈으로 하나하나 보는건 힘드니, 답과 쉽게 비교해보고 싶습니다.
2-4. Accuracy 확인하기
scikit learn에 accuracy를 확인해주는 함수가 있습니다. 함수 이름은 accuracy_score 입니다.
from sklearn.metrics import accuracy_score
정답, 예측값 순서로 옵션을 줍니다.
accuracy_score(iris.target, y_pred_tr)

99.33%의 정확도를 갖고있는 것을 확인할 수 있습니다. 우리는 scikit learn이란 "Frame work"를 통해 이렇게 예측을 할 수 있습니다.
그런데 이 150개 데이터가 이 세상에 있는 모든 setosa, vergicolor, virginica 모든 iris를 대변할 수 없기 때문에, 이 높은 확률을 신뢰할 수 없습니다. 이렇게 너무 높게 나오면 "과적합"을 의심해봐야 합니다. 그럼 과적합은 무엇일까요? 다음 시간에 공부해보겠습니다.
'머신러닝' 카테고리의 다른 글
| Decision Tree를 사용한 Iris 분류_데이터 나누기 (0) | 2024.02.23 |
|---|---|
| Decision Tree를 사용한 Iris 분류_과적합 (0) | 2024.02.22 |
| Entropy와 Gini 계수 (0) | 2024.02.21 |
| Decision Tree를 사용한 Iris 분류_데이터 관찰 (1) | 2024.02.19 |
| X, y 용어 정리 및 머신러닝 지도학습 의 큰 흐름 (0) | 2023.01.12 |



