1. Intro
머신러닝을 처음 공부할 때 주로 사용되는 붓꽃, Iris의 분류 데이터를 학습해보겠습니다.
Iris는 세상에 여러 종이 있지만 우리가 다룰 scikit learn 모듈의 데이터셋에서는 setosa, vergicolor, virginica의 총 3종만 취급합니다.
Iris의 꽃받침(sepal)의 너비와 길이, 꽃잎(petal)의 너비와 길이 총 4개의 데이터와 어떤 종인지 0, 1, 2로 나타나 있습니다.
우리는 각 꽃의 4가지 특징(feature)을 통해 어떤 종(species)인지 분류하고, 분류 알고리즘인 Decision Tree를 사용해 머신러닝을 해보겠습니다.
2. Iris 데이터 불러오기
from sklearn.datasets import load_iris
iris = load_iris()
iris
scikit learn의 datasets 모듈의 load_iris() 함수를 불러옵니다.
iris라는 변수에 넣고 프린트하면 위와 같은 결과를 얻을 수 있는데요,
dictionary 형태임을 알 수 있고, 'data'라는 key가 존재하는 걸 알 수 있습니다.
3. Iris 데이터 확인하기
우선 key가 어떤게 있는지 확인해보겠습니다.
iris.keys()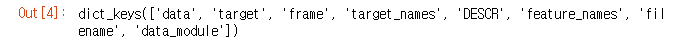
data, target, frame, target_names, DESCR, feature_names, filename, data_module이 있는걸 확인했습니다.
각 키가 어떤걸 나타내는지 알기 전에 우선, scikit learn의 datasets에서 가져온 데이터들은 DESCR key를 꼭 갖고있는데 이를 열어보면 해당 데이터에 대한 자세한 설명이 적혀있습니다.
우선 DESC를 확인해보겠습니다.
print(iris['DESCR']) #iris.DESCR로 적어도 무관함
이처럼 load_iris() 데이터에 대한 설명이 나와있습니다. Fisher 아저씨가 만들었다는 친절한 설명과 함께 말이죠.
다시 돌아와서, 우리는 각 데이터가 어떤 종인지 적힌 데이터를 확인해야 합니다.
target key를 확인해보겠습니다.
print(iris['target']) #iris.target으로도 호출 가능

0은 setosa, 1은 vergicolor, 2는 virginica로 각각 50개씩 총 150개의 데이터가 있는 걸 확인했습니다. 그럼 target_names에는 150개에 각각 setosa, vergicolor, virginica가 적혀있는지도 확인해보겠습니다.
print(iris['target_names'])
아쉽게도 친절한건 target 까지인걸 확인했습니다. 나중에 매칭해야겠군요...
데이터가 들어있는 가장 중요한 data key를 확인해보겠습니다.
iris['data']

첫번째 iris의 데이터는 sepal length 5.1 selap width 3.5, petal length 1.4, petal length 0.2라는 뜻이네요.
이 데이터는 label이 0이고 이는 setosa를 나타냅니다.
4. Dataframe으로 정리하기
Iris 데이터를 좀 더 보기쉽게 dataframe으로 만들어보겠습니다.
pandas의 dataframe를 불러와야겠네요.
import pandas as pd
iris_pd = pd.DataFrame(iris.data, columns=iris.feature_names)
#iris.data를 value로 두고, column이름을 feature name으로 하겠다는 뜻
iris_pd.head()
품종 정보도 column에 포함시켜보겠습니다.
iris_pd['species'] = iris.target
iris_pd.head()

5. 어떤 특징으로 분류해야 하는지 확인하기
5-1. box plot 그래프 그리기
일단 그래프를 그려 보기쉽게 각 특징에 따른 종 분류가 가능한지 확인해보겠습니다.
box plot을 그려서 sepal length에 따라 3종이 어떤 차이를 보이는가 부터 확인해보겠습니다.
import matplotlib.pyplot as plt
import seaborn as sns
#!pip install seaborn
sns.boxplot(x='sepal length', y=species', data=iris_pd, orient='h');
#seaborn에서는 수평바로 그리라는걸 orient='h'로 옵션을 준다.
#세미콜론을 안하면 위에 주석이 적혀있다.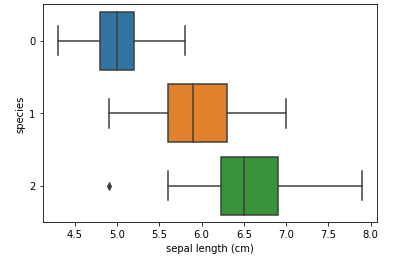
그림이 너무 작으니까 크기를 설정해보겠습니다.
plt.figure(figsize=(12,6))
sns.boxplot(x='sepal length (cm)',y='species',data=iris_pd, orient='h');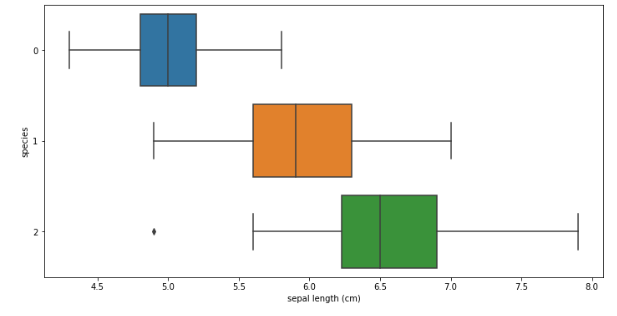
세 개 품종이 다 겹치는 구간이 있어서 sepal length로는 세 개 품종을 구분하기 어렵습니다.
virginical의 outlier중 하나가 특별히 sepal length가 작은 값이 있네요.
이번에는 sepal width로 보겠습니다.
plt.figure(figsize=(12,6))
sns.boxplot(x='sepal width (cm)',y='species',data=iris_pd, orient='h');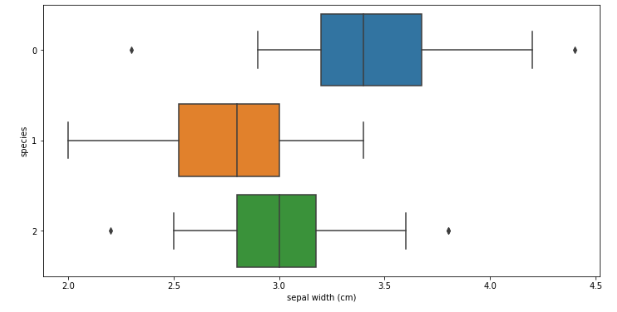
이 친구는 더 알 수 없네요... 이번에는 petal length로 확인해보겠습니다.
plt.figure(figsize=(12,6)
sns.boxplot(x='petal length (cm)', y='species', data=iris_pd, orient='h');
오 petal length로는 setosa를 확실히 구분할 수 있습니다
이번에는 petal width로 봐보겠습니다.
plt.figure(figsize=(12,6)
sns.boxplot(x='petal width (cm)', y='species', data=iris_pd, orient='h');
#x는 dataframe에서 복사 붙여넣기로 집어넣는 것이 오류를 최소화 하는 좋은 방법입니다.
petal width만으로도 setosa를 구분할 수 있네요.
petal이라는 특성으로 setosa만큼은 구분할 수 있을 것 같습니다!
그러나 네개 특성 하나씩을 써서는 3종을 구분할 수 없습니다... 그러면 pair plot을 그려서 봐볼까요?
sns.pairplot(iris_pd, hue='species')
#hue 옵션을 줘서 species로 구분을 해주라고 명령5-2. pair plot 그래프 그리기
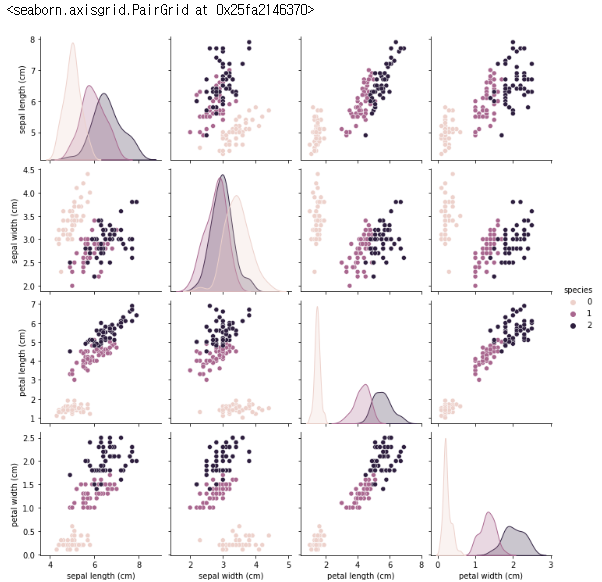
pair plot을 통해 확인한 결과 밑에서 세번째 그래프를 확인해 보면, petal length에 따른 petal width가 특별히 3종이 잘 구분됨을 볼 수 있습니다.
확실한건 일단 setosa는 분류 가능합니다.
- setosa : petal length가 대충 2.5보다 작으면 setosa다 라고 할 수 있다.
- virsocolor : petal length가 2.5보다 크면서 petal width가 1.6보다 작은 경우
- virginica : petal length가 2.5보다 크면서 petal width가 1.6보다 큰 경우
이 내용을 질문(조건문)으로 순차적으로 표현할 수 있을까요?라고 생각하는 것이 Decision Tree 라고 하는 알고리즘입니다.
6. 대략적인 Decision Tree
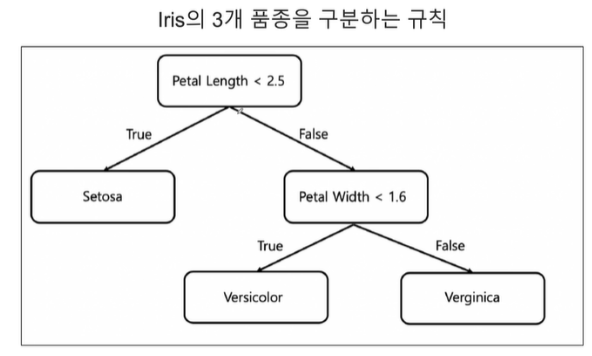
우리가 직접 나누기로 결정한 규칙을 정한게 위와 같은 Decision Tree라는 방식입니다.
이 Decision Tree가 최선인가? 라고 묻는다면 위와 같은 결정방식을 통해 최선임을 증명해야합니다.
'머신러닝' 카테고리의 다른 글
| Decision Tree를 사용한 Iris 분류_데이터 나누기 (0) | 2024.02.23 |
|---|---|
| Decision Tree를 사용한 Iris 분류_과적합 (0) | 2024.02.22 |
| Entropy와 Gini 계수 (0) | 2024.02.21 |
| Decision Tree를 사용한 Iris 분류_데이터 학습 및 예측 (0) | 2024.02.21 |
| X, y 용어 정리 및 머신러닝 지도학습 의 큰 흐름 (0) | 2023.01.12 |



