이번에는 wine 데이터로 살펴보겠습니다. 지난시간에 썼던 iris 데이터는 feature가 4개밖에 없었지만 wine 데이터는 feature가 꽤 많았던걸로 기억합니다.
wine_url = 'http://raw.githubusercontent.com/PinkWink/ML_tutorial/master/dataset/wine.csv'
wine = pd.read_csv(wine_url, sep=',', index_col=0)
wine.head()
wine_X = wine.drop(['color'], axis=1)
wine_y = wine['color']X와 y로 나누구요, 이번에도 scalilng 시켜보겠습니다.
wine_ss = ss.fit_transform(wine_X)이렇게 얻은 scaling 된 X데이터를 pca를 돌려야겠죠, pca fit, transform 시키는 함수였던 get_pca_data()함수를 들고옵니다.
pca_wine, pca = get_pca_data(wine_ss, n_components=2)이렇게 얻은 pca에서 설명력을 print 시켜주는 함수를 또 만들겠습니다.
def print_variance_ratio(pca):
print('varience_ratio :', pca.explained_variance_ratio_)
print('sum of varience_ratio :', np.sum(pca.explained_variance_ratio_))
print_variance_ratio(pca)varience_ratio : [0.25346226 0.22082117]
sum of varience_ratio : 0.4742834274323619
pca_wine을 넣어야 하는거 아닌가 싶지만 pca_wine은 pca.transform시킨후의 wine 데이터입니다. 그냥 array만 갖고있는것이죠.
주성분을 두개로 줄였더니 50%가 안되네요...
데이터프레임으로 만들어서 pairplot으로 관찰해보겠습니다.
pca_columns = ['PC1', 'PC2']
pca_wine_pd = pd.DataFrame(pca_wine, columns=pca_columns)
pca_wine_pd['color'] = wine_y.values
pca_wine_pd.head()
sns.pairplot(pca_wine_pd, hue='color', height=5, x_vars=['PC1'], y_vars=['PC2'])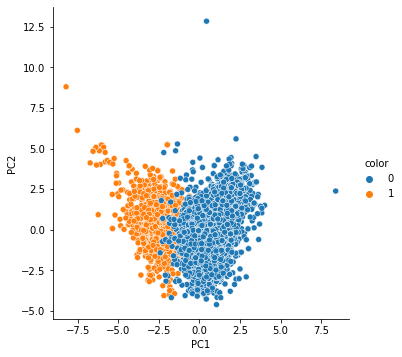
생각보다 잘 나뉘어지는 걸 알 수 있습니다.
머신러닝을 돌려 accuracy를 확인해볼까요? 먼저 pca를 적용하기 전 scaling 만했을때의 정확도입니다.
rf_scores(wine_ss, wine_y)Score : 0.9935352638124
pca_X = pca_wine_pd[['PC1', 'PC2']]
rf_scores(pca_X, wine_y)Score : 0.981067803635933
%%time으로 확인해보니까 시간이 줄어드는걸 확인했습니다. score가 98%로 떨어지지만, 나쁘지않습니다.
주성분 3개로 바꿔보겟습니다.
pca_wine, pca = get_pca_data(wine_ss, n_components=3)
print_variance_ratio(pca)varience_ratio : [0.25346226 0.22082117 0.13679223]
sum of varience_ratio : 0.61107566218387
주성분을 3개로 하니까 sum값이 61%로 높아지는걸 볼 수 있습니다.
주성분이 3개니까 pairplot 말고 3D로 표현하는 것도 해보겠습니다. 주성분이 3개니까요.
pca_columns = ['PC1', 'PC2', 'PC3']
pca_wine_pd = pd.DataFrame(pca_wine, columns=pca_columns)
pca_wine_pd['color'] = wine_y.values
pca_wine_pd
pca_X = pca_wine_pd[pca_columns]
rf_scores(pca_X, wine_y)Score : 0.9832236631728548
0.2% 정확도가 높아졌네요 ㅎㅎ
3Dplot을 그려보겠습니다. 3D는 plotly express의 scatter_3D라는 함수로 만들겠습니다.
import plotly_express as px
fig = px.scatter_3d(pca_wine_plot, x='PC1', y='PC2', z='PC3', color='color', symbol='color', opacity=0.4)
#color는 color컬럼에 따라 구분하고 symbol도 color 컬럼에 따라 구분하라는 뜻
fig.update_layout(margin=dict(l=0, r=0, b=0, t=0))
fig.show()color는 color컬럼에 따라 구분하고 symbol도 color 컬럼에 따라 구분하라는 뜻입니다.
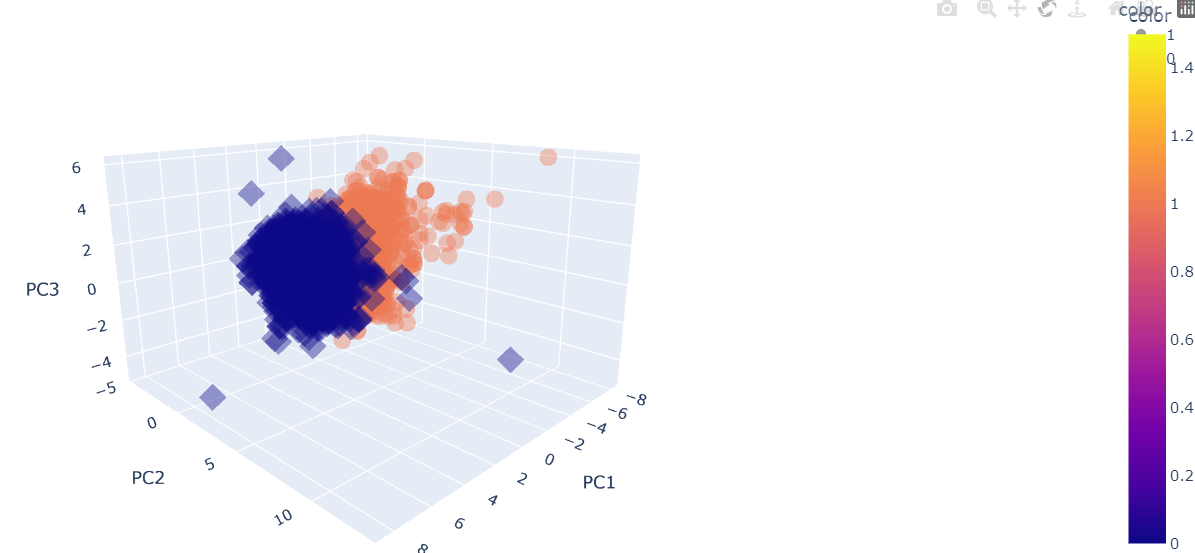
이 강의에서 알아야 하는 점은 코드가 아니라, pca는 새로운 특성을 만들어낸다. 주성분은 설명력이라는 변수에 의해 얼마나 데이터를 설명할 수 있는지도 알 수 있다. 라는 점입니다 :D
'머신러닝 > PCA(Principal Component Analysis)' 카테고리의 다른 글
| MNIST using PCA and kNN (1) | 2024.06.04 |
|---|---|
| HAR using PCA (0) | 2024.06.04 |
| PCA - eigenface (0) | 2024.06.01 |
| PCA - iris 데이터 (0) | 2024.06.01 |
| PCA란? (0) | 2024.05.31 |



