
머신러닝에서는 raw data가 있고, 이 raw data를 feature engineering 시킵니다.
feature engineering은 특성을 관찰하고, 머신러닝을 더 잘 수행하기 위해서 새로운 특성을 만들어내거나 가공하는 단계를 말합니다.
그 후에 train, validation, test로 데이터를 나누었습니다.
train 데이터를 가지고 모델을 만들고 훈련 결과를 확인했었죠, 그리고 그 안에서 찾은 모델, validation 모델을 가지고 다시 결과를 확인합니다.
이걸 보면서 hyperparameter를 tuning합니다. 그런데 이게 말이 어려워서 그렇지 노가다를 의미합니다. 즉 손으로 하나하나 일일히 수정해야 하는 단계를 말합니다.
그리고 난 다음에 모델이 다 완료되면, test를 하는겁니다.
우리가 해본 모델은 결정나무 모델 뿐이기 때문에, 아직 우리가 튜닝해볼 만한 것은 max_depth 하나 뿐입니다.
어떻게 튜닝하는지 한번 알아보겠습니다.
저번에 사용한 wine 데이터를 가져와 진행해보겠습니다.
import pandas as pd
red_url = 'https://raw.githubusercontent.com/PinkWink/ML_tutorial/master/dataset/winequality-red.csv'
white_url = 'https://raw.githubusercontent.com/PinkWink/ML_tutorial/master/dataset/winequality-white.csv'
red_wine = pd.read_csv(red_url, sep=';')
white_wine = pd.read_csv(white_url, sep=';')
red_wine['color'] = 1.
white_wine['color'] = 0.
wine = pd.concat([red_wine, white_wine])
wine['taste'] = [1. if grade>5 else 0. for grade in wine['quality']]
X = wine.drop(['taste', 'quality'], axis=1)
y = wine['taste']
여기서 Grid search 이야기를 해보겠습니다.
우리는 머신러닝을 하면서 매번 하이퍼파라미터를 수정할 수 없습니다. 알고리즘이 여러개거나 모델이 복잡해지면, 각 단계별로 수정해야할 하이퍼파라미터가 많아집니다. 그렇게되면 경우의 수가 엄청 많아집니다. 이걸 다 코드로 짜는 것도 쉬운일이 아닙니다.
여기서 등장하는 것이 GridSearchCV입니다. 우선 parameters를 지정해주고 tree 설정해줍니다. 그 후에 Grid Search CV한테 이 지정된 분류기에 내가 말한 파라미터를 알아서 니가 알아서 cv=5 5겹 kfold로 fit하라고 명령해줄 수 있습니다.
from sklearn.model_selection import GridSearchCV
from sklearn.tree import DecisionTreeClassifier
params = {'max_depth':[2,4,7,10]}
wine_tree = DecisionTreeClassifier(max_depth=2, random_state=13)
이 다음에 트리에 핏하는게 아니라 새로운라는 변수에 초기화, 인스턴시에이션 시킵니다. 변수 이름은 gridsearch라고 해보겠습니다.
gridsearch = GridSearchCV(estimator=wine_tree, param_grid=params, cv=5)
여기서 estimator는 분류기를 뜻하고, param_grid에 params를 넣어줍니다. cv 즉 교차검증 횟수는 5번으로 하겠습니다. 여기서 참고로 가끔 param_grid에 n_jobs 옵션을 주는 경우가 있는데 pre_dispatch=n_jobs를 넣고 그전에 n_jobs=16을 선언해주면 CPU의 코어가 16개면 16개 코어를 다 활용한다는 뜻입니다. 이런게 있다 정도만 알아두면 될 것 같습니다.
gridsearch.fit(X, y)
이렇게하면 gridsearch가 train_test_split을 알아서 해줍니다.

이제 GridSearch CV의 결과를 관찰해보겠습니다.
pprint라는 각각의 요소를 다른 줄에 출력하는 모듈이라 쓰고 이쁘게 나타내는 모듈을 가져오겠습니다.
import pprint
pp = pprint.PrettyPrinter(indent=4) #indent는 4칸으로 잡아줍니다.
pp.pprint(gridsearch.cv_results_) #아까 만든 gridsearch라는 변수의 cv_results_를 프린트 하라는 명령을 줍니다.
indent는 들여쓰기로 4칸을 잡아주었고, 아까 만든 gridsearch라는 변수의 cv_results_를 프린트 하라는 명령을 줍니다.4
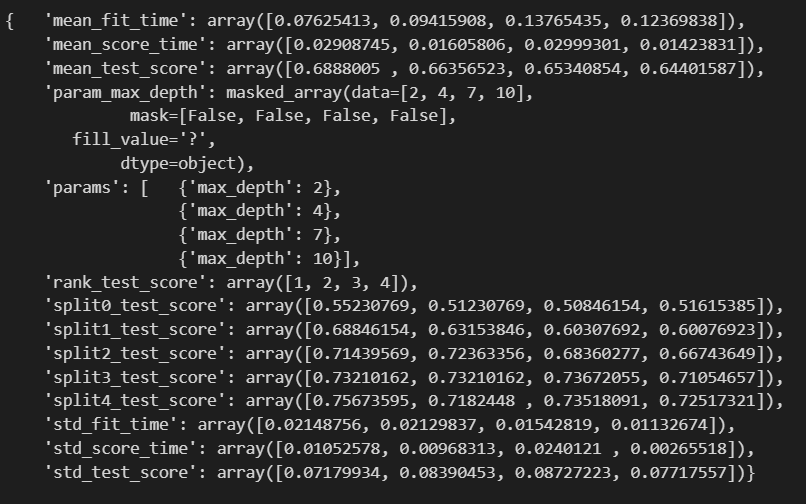
보기좋게 각각의 요소별로 다른줄에 나타냈습니다.
5등분을 했으므로 fit time은 0초를 제외한 4개의 시간이 나옵니다.
mean test score도 나오네요. 그리고 무엇보다 max_depth 2,4,7,10으로 돌려본 결과, rank_test_score를 보면 2,4,7,10 순으로 1,2,3,4등이라고 말합니다. 그럼 max depth가 2일때가 가장 좋다는 뜻인데요. 이걸 관찰해보도록 하겠습니다.
제일 최고의 성능을 가진 모델이 뭔지, 가장 높은 score가 뭔지 등등 알고싶으면, best_함수를 쓰면됩니다.
먼저 최고의 모델은 best_estimator_로 알 수 있습니다.
gridsearch.best_estimator_
그리고, best score는 best_score_로 알 수 있습니다.
gridsearch.best_score_
# 69%의 확률이네요. 그렇다면 best parameter는 뭔지 알고싶으면 best_params_를 쓰면 됩니다.
gridsearch.best_params_
이렇게하면 gridsearch가 알아서 내가 사용한 경우의 수를 다 알아서 확인해줍니다.
만약 pipeline을 적용한 모델에 GridSearch를 적용하고 싶다면 아래 코드를 사용하면 됩니다.
우선 pipeline 코드를 쓰겠습니다.
from sklearn.pipeline import Pipeline
from sklearn.tree import DecisionTreeClassifier
from sklearn.preprocessing import StandardScaler
estimators = [('scaler', StandardScaler()),
('clf', DecisionTreeClassifier(random_state=13))]
pipe = Pipeline(estimators)
여기까지가 pipeline 코드이고, grid search를 적용할겁니다.
적용을 위해서 파라미터에 pipeline에 속성을 주는 걸로 언더바 두개를 붙이는 걸 기억해야합니다.
코드를 보면 이해할 수 있습니다.
param_grid = [ {'clf__max_depth' : [2, 4, 7, 10]}]
GridSearch = GridSearchCV(estimator=pipe, param_grid=param_grid, cv=5)
GridSearch.fit(X, y)
얘도 똑같이 grid search에 대해서 best를 물어볼 수 있습니다.
GridSearch.best_estimator_
GridSearch.best_score_
여기서 깔끔하게 정리하는 방법에 대해 간단히 말씀드리겠습니다.
방금 만든 GridSearch 변수의 cv_results_를 호출해서 dataframe으로 만듭니다.
import pandas as pd
score_df = pd.DataFrame(GridSearch.cv_results_)
score_df
깔끔하게 데이터프레임으로 만들 수 있습니다. 그러나 요소가 많아 스크롤이 생깁니다.
꼭 필요한 것만 추려보겠습니다.
score_df[['params','rank_test_score', 'mean_test_score', 'std_test_score']]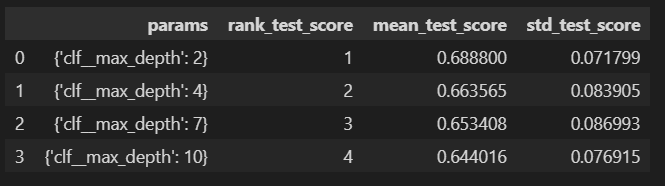
max depth가 2일때 평균 근처에 더 머물러있고 score도 높아 이 모델이 4개중에 가장 best 모델이라고 말할 수 있습니다.
'머신러닝 > Preprocessing' 카테고리의 다른 글
| 교차검증 (cross validation) (0) | 2024.03.06 |
|---|---|
| Scikit-learn Pipeline으로 만들기 (1) | 2024.03.05 |
| Decision Tree를 이용한 Wine 데이터 분석_이진분류 (0) | 2024.03.04 |
| Decision Tree를 이용한 Wine 데이터 분석_데이터 처리 (1) | 2024.03.01 |
| Decision Tree를 이용한 Wine 데이터 분석_데이터 확인 (1) | 2024.02.29 |



