단순히 데이터를 받아서 사용했을 뿐인데, 직접 공부하면서 코드를 사용하다보면 혼돈이 있을 수 있습니다. 함수나 클래스를 같이 사용하는 경우를 말하는데, 코드의 실생 순서에 혼돈이 있을 수 있습니다. 이런 경우 전처리 과정이나 알고리즘의 반복실행 시 클래스(class)로 만들어서 진행해도 되지만, sklearn 유저에게는 꼭 그럴 필요가 없이 준비된 기능이 있습니다. 그것이 바로 pipeline입니다.
pipeline을 사용해서 지난시간의 wine 데이터를 처리해보겠습니다.
import pandas as pd
red_url = 'https://raw.githubusercontent.com/PinkWink/ML_tutorial/master/dataset/winequality-red.csv'
white_url = 'https://raw.githubusercontent.com/PinkWink/ML_tutorial/master/dataset/winequality-white.csv'
red_wine = pd.read_csv(red_url, sep=';')
white_wine = pd.read_csv(white_url, sep=';')
red_wine['color'] = 1.
white_wine['color'] = 0.
wine = pd.concat([red_wine, white_wine])
X = wine.drop(['color'], axis=1)
y = wine['color']
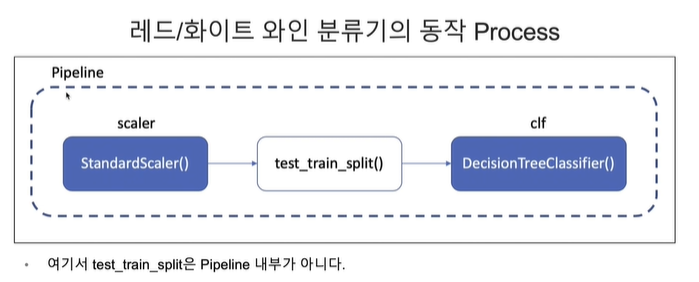
Pipeline 내 구성은 아래와 같이 하려고 합니다.
Scaler - test_train_split() - clf
우리가 했던 scaler와 clf를 가져와보면, StandardScaler()-test_train_split()-DecisionTreeClassifier() 순서입니다.
여기서 test_train_split은 pipeline 내부가 아니고 scaler와 clf만이 pipeline에 해당합니다.
참고로 split은 중간에 넣어도 되고, 밖에 넣어도 됩니다.
이 부분의 pipeline을 코드로 구현하면, 아래 코드가 다입니다.
from sklearn.pipeline import Pipeline
from sklearn.tree import DecisionTreeClassifier
from sklearn.preprocessing import StandardScaler
estimators = [('scaler', StandardScaler()),('clf', DecisionTreeClassifier())]
pipe = Pipeline(estimators)
이 때 주의할 점으로 리스트 형으로 튜플로 scaler clf 두개를 넣어준 변수를 Pipeline()을 시켜줍니다.
이제 pipe를 확인해보겠습니다.
pipe
pipe.steps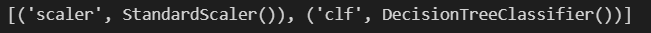
scaler단계에서는 StandardScaler()를 불러오고, clf단계에서는 DecisionTreeClassifier()를 불러온다는 뜻입니다.
몇 번째 단계만 호출하려면 아래와 같이 부를 수도 있습니다.
pipe.steps[0], pipe.steps[1]
pipe의 단계이름으로도 호출할 수 있습니다.
pipe['scaler']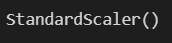
pipe[0]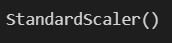
set_params 함수를 사용해 Classification 속성을 추가하겠습니다.
언더바 2개를 쓰면 해당 단계에 속성을 추가할 수 있습니다.
먼저 clf에 max_depth를 2로 주고, random_state=13으로 잡겠습니다.
pipe.set_params(clf__max_depth=2)
pipe.set_params(clf__random_state=13)
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=13,
stratify=y) #stratify는 분포를 맞추라는 뜻이었습니다.
#이렇게하면 X_train 데이터가 잘 반환되어 와있습니다.
X_train
기억나시나요? stratify를 y의 분포와 같이 주면 y의 분포와 동일하게 분포가 맞춰집니다.
원래대로 하면 scaler를 통과시키고, 분류기를 학습시켰는데 이를 pipe라는 변수에 이미 선언을 해뒀으니 pipe를 사용합니다.
pipe.fit(X_train, y_train)
from sklearn.metrics import accuracy_score
y_pred_tr = pipe.predict(X_train)
y_pred_test = pipe.predict(X_test)
print('Train acc : ', accuracy_score(y_train, y_pred_tr))
print('Test acc : ', accuracy_score(y_test, y_pred_test))
트리 모델구조를 확인해보겠습니다.
import sklearn.tree as tree
import matplotlib.pyplot as plt
plt.figure(figsize=(12,6))
tree.plot_tree(pipe['clf'], feature_names=X.columns, rounded=True, filled=True)
plt.show()
주의할 점으로 pipe가 아닌 pipe['clf']를 변수로 넣어줘야 한다는 것입니다.
'머신러닝 > Preprocessing' 카테고리의 다른 글
| GridSearchCV을 통한 하이퍼파라미터 튜닝 (1) | 2024.03.07 |
|---|---|
| 교차검증 (cross validation) (0) | 2024.03.06 |
| Decision Tree를 이용한 Wine 데이터 분석_이진분류 (0) | 2024.03.04 |
| Decision Tree를 이용한 Wine 데이터 분석_데이터 처리 (1) | 2024.03.01 |
| Decision Tree를 이용한 Wine 데이터 분석_데이터 확인 (1) | 2024.02.29 |



