저번 시간에 확인한 red와 white wine에 대한 데이터를 이제 처리해보겠습니다. 머신러닝을 할 때에는 feature롸 label로 데이터를 분류한 뒤 학습을 시키고 예측을 시킨뒤 정확도를 확인하고, Decision Tree인 경우 Tree가 어떻게 생겼는지 확인했었습니다. 이번 시간에는 그 작업을 진행하겠습니다.
3. 데이터 처리
3-1. 데이터 분류하기
레드인지 화이트인지 분류하는 머신러닝을 진행해보려고 합니다.
먼저 color가 적히지 않은 wine과 color가 적힌 wine 데이터를 각각 만들겠습니다.
feature(문제)인 X를 만들고, label(정답)인 y를 만들겠습니다. color 컬럼만 따로 들고왔습니다.
마지막으로 데이터 확인해주겠습니다.
X = wine.drop(['color'], axis=1)
y = wine['color']
X.head()
y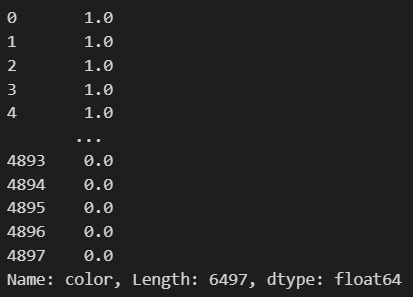
데이터를 훈련용과 테스트용으로 나눠주겠습니다. 추가로 y 데이터가 몇개씩 분류되는지 확인해보겠습니다.
from sklearn.model_selection import train_test_split
import numpy as np
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=13)
#y 데이터가 몇개씩 분류되는지 확인해보겠습니다.
np.unique(y_train, return_counts=True)
0이 약 4000개와 1이 약 1000개 정도로 분류되었습니다.
이제 plotly.express로 red와 white와인이 훈련용과 테스트용으로 얼마나 잘 구분되었는지 확인해보겠습니다.
일단은 histogram 두 종류를 넣어야 하기 때문에, graphic_objects를 호출합니다.
그리고 X_train과 X_test의 quality 그래프를 겹쳐보겠습니다.
import plotly.graph_objects as go
fig = go.Figure() #Matplotlib때 plt.figure() 호출하듯이 Figure()를 호출합니다.
fig.add_trace(go.Histogram(x=X_train['quality'], name='Train')) #fig에 go의 histogram을 가져오라는 뜻입니다.
fig.add_trace(go.Histogram(x=X_test['quality'], name='Test')) #이건 label 역할입니다.
fig.update_layout(barmode='overlay') #두 개를 겹쳐그릴 것이기 때문에 overlay를 줍니다.
fig.update_traces(opacity=0.7)
fig.show()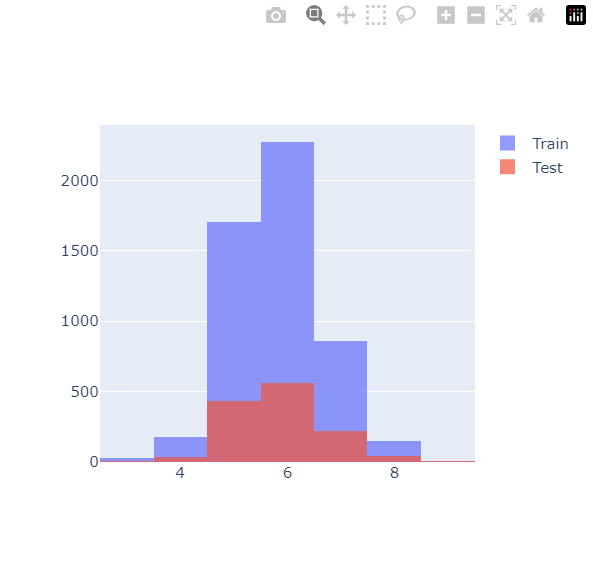
등급별로 골고루 나뉜 것 같습니다. 이 상태에서 max_depth를 2로두고 Decision Tree fit시켜보겠습니다.
3-2. Decision tree를 사용한 머신러닝 (전처리 없이)
from sklearn.tree import DecisionTreeClassifier
wine_tree = DecisionTreeClassifier(max_depth=2, random_state=13)
wine_tree.fit(X_train, y_train) #feature와 label 꼭 주기
학습을 완료했으니 예측해보겠습니다.
이미 학습한 wine_tree로 X_train을 예측해서 y_pred_tr을 구하고 이를 y_train과 비교할 예정입니다.
from sklearn.metrics import accuracy_score
y_pred_tr = wine_tree.predict(X_train)
y_pred_test = wine_tree.predict(X_test)y_pred_tr
0, 1, 0, 1이 나오는걸 보면 red, white를 나타내는걸 알 수 있습니다.
정답과 예측값으로 정확도를 조사해보겠습니다.
accuracy_score(y_train, y_pred_tr)
95%정도가 나오네요, test도 볼까요?
accuracy_score(y_test, y_pred_test)
얘도 95%정도가 나옵니다. accuracy 측면에서 두 개의 성능은 유사하다는 걸 확인했습니다.
3-3. 데이터 전처리 후 Decision tree를 사용한 머신러닝
다음 그래프 그릴때 도움을 받기위해 X의 컬럼을 조사해보겠습니다.
X.columns
우리가 뭘더 해야할까? 보통 무슨 방법을 더 하는가?를 살펴보면, decision tree는 보통 scaler를 사용한 전처리에 큰 영향을 받지 않습니다. Gini 계수에서 feature의 편향이 영향을 주지 않기때문에 전처리를 해보겠습니다. box plot도 같이 그려 확인해볼까요?
fig = go.Figure()
# 위에서 조회한 X의 컬럼들을 보고 긁어옵니다.
fig.add_trace(go.Box(y=X['fixed acidity'], name='fixed acidity'))
fig.add_trace(go.Box(y=X['chlorides'], name='chlorides'))
fig.add_trace(go.Box(y=X['quality'], name='quality'))
fig.show()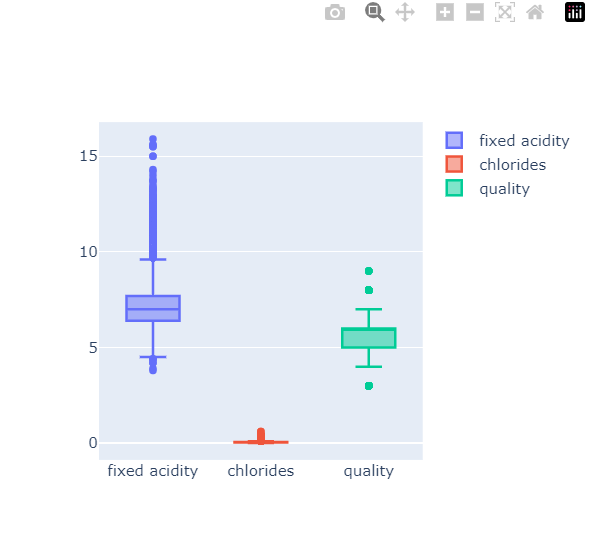
우선, fixed acidity와 chlorides가 차이가 꽤 큽니다. 이 처럼 column들 간의 범위의 격차가 심한 경우에 머신러닝이 잘 안될'수도' 있습니다. 안된다가 아닙니다.
min max가 좋을지 standard가 좋을지 모릅니다. 해봐야압니다. 둘다 해보겠습니다.
from sklearn.preprocessing import MinMaxScaler, StandardScaler
mms = MinMaxScaler()
ss = StandardScaler()
mms.fit(X)
ss.fit(X)
X_mms = mms.transform(X)
X_ss = ss.transform(X)X_mms
array([]) 형태이므로 pd.DataFrame으로 바꿔주겠습니다.
pd.DataFrame(X_mms)
column 이름이 안들어가있으므로, X.columns로 이름을 넣어주겠습니다.
X_mms_pd = pd.DataFrame(X_mms, columns=X.columns)
X_ss_pd = pd.DataFrame(X_ss, columns=X.columns)
X_mms_pd
X_ss_pd
다시 그려보겠습니다. 먼저 min max scaler를 그려보겠습니다.
fig = go.Figure()
fig.add_trace(go.Box(y=X_mms_pd['fixed acidity'], name='fixed acidity'))
fig.add_trace(go.Box(y=X_mms_pd['chlorides'], name='chlorides'))
fig.add_trace(go.Box(y=X_mms_pd['quality'], name='quality'))
fig.show()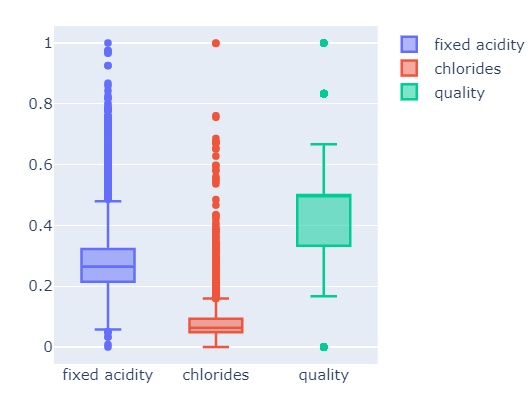
standard scaler 도 그려보겠습니다.
fig = go.Figure()
fig.add_trace(go.Box(y=X_ss_pd['fixed acidity'], name='fixed acidity'))
fig.add_trace(go.Box(y=X_ss_pd['chlorides'], name='chlorides'))
fig.add_trace(go.Box(y=X_ss_pd['quality'], name='quality'))
fig.show()
이런걸 함수로 만들면 더 편할 것입니다.
def px_box(target_df):
fig = go.Figure()
fig.add_trace(go.Box(y=target_df['fixed acidity'], name='fixed acidity'))
fig.add_trace(go.Box(y=target_df['chlorides'], name='chlorides'))
fig.add_trace(go.Box(y=target_df['quality'], name='quality'))
fig.show()
px_box(X_mms_pd), px_box(X_ss_pd)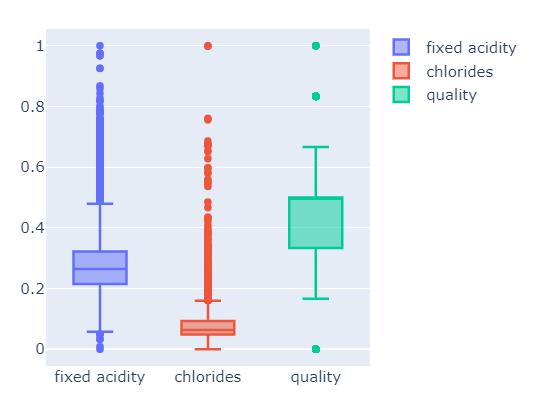
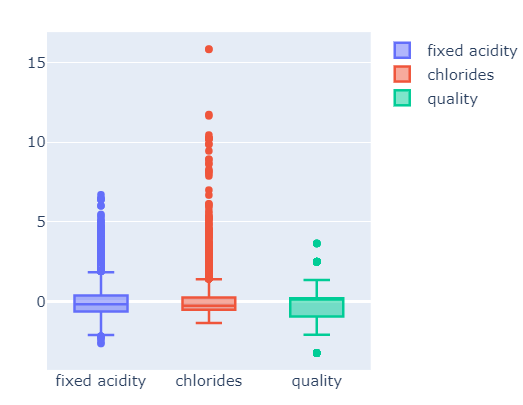
뭐가 더 좋은지는 모르겠습니다. min max를 적용해서 학습시켜보겠습니다.
X_train, X_test, y_train, y_test = train_test_split(X_mms_pd, y, test_size=0.2, random_state=13)
wine_tree.fit(X_train, y_train)
print('Train Acc',accuracy_score(y_train, y_pred_tr))
print('Test Acc',accuracy_score(y_test, y_pred_test))
큰 차이가 보이지 않습니다. 다시 이야기하지만 결정나무에서는 이러한 전처리가 큰 효과가 없습니다.
standard scaler 데이터로도 학습해보겠습니다.
X_train, X_test, y_train, y_test = train_test_split(X_ss_pd, y, test_size=0.2, random_state=13)
wine_tree.fit(X_train, y_train)
print('Train Acc',accuracy_score(y_train, y_pred_tr))
print('Test Acc',accuracy_score(y_test, y_pred_test))
완전히 같은 데이터가 나오네요... Decision Tree라서 그렇습니다.
Tree를 그려보면 뭔진 몰라도 total sulfur dioxide가 중요한 역할을 하나봅니다. 총 이산화황 TSO2를 의미하네요
그럼 이제 레드 와인과 화이트 와인을 구분하는 중요 특성을 살펴보겠습니다.
dict(zip(X_train.columns, wine_tree.feature_importances_))컬럼이름은 X_train 컬럼이름을 그대로 들고오고, 분류는 tree구조, feature는 feature_importances_라고 하면 됩니다. zip후 dict 시켜주면 둘을 연결시켜줍니다.
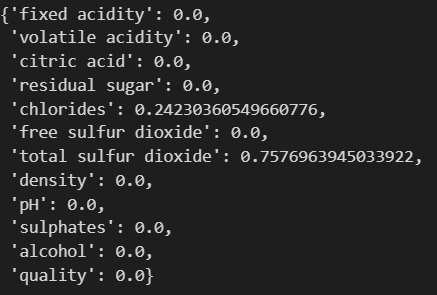
total sulfur dioxide와 chlorides가 큰 영향을 미치는 것을 확인했습니다.
두 개만 나오는 것은 tree에서 max_depth=2로 줬기 때문이고, max_depth를 4로 주면 4개가 나올겁니다.
'머신러닝 > Preprocessing' 카테고리의 다른 글
| Scikit-learn Pipeline으로 만들기 (1) | 2024.03.05 |
|---|---|
| Decision Tree를 이용한 Wine 데이터 분석_이진분류 (0) | 2024.03.04 |
| Decision Tree를 이용한 Wine 데이터 분석_데이터 확인 (1) | 2024.02.29 |
| Scaling (2) | 2024.02.28 |
| Label encoder (1) | 2024.02.27 |



