728x90
머신러닝의 대표적인 도구 scikit learn을 사용 할 때, 많이 하는 절차 중에 대표적인 두가지(label encoder와 scaler) 거기서 scaler에서 가지를 쳐서 총 4가지에 대한 공부를 하겠습니다. scaler에는 min_max scaler, standard scaler, robust scaler가 있습니다.
오늘은 먼저 Label encoder에 대해 공부해보겠습니다.
학습용 데이터를 만들어보겠습니다.
import pandas as pd
df = pd.DataFrame( {'A' : ['a', 'b', 'c', 'a', 'b'],
'B' : [1, 2, 3, 1, 0]})
df
머신 러닝을 할 때는 숫자로 되어있어야 처리하기 쉽습니다. 이렇게 문자로 된 데이터를 숫자로 자동으로 바꿔주는 모듈이 Label encoder 입니다.
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
le.fit(df['A'])
이제 fit()시킨 le에서 제대로 A 컬럼을 갖고있는지 확인해보겠습니다. label encoder는 해당 데이터의 내용을 숫자로 바꾸기 때문에 내용을 잘 갖고있는지 확인해야합니다.
le.classes_
방금 내가 fit 시켰던 변수에 a, b, c가 있었습니다.
이제 transform 시키면 숫자로 바꿀 수 있습니다.
le.transform(df['A'])
df['le_A'] = le.transform(df['A'])
df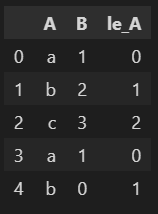
이걸 한번에 할 수 있는 방법이 있습니다.
le.fit_transform(df['A'])
각각의 변수를 따로 transform()시키는 방법도 있습니다.
le.transform(['a']),le.transform(['b']),le.transform(['c'])
#le.transform(['d']) #준적없다고 뜬다.
여기서 le.transform(['d'])를 입력하면 에러가 뜹니다. A컬럼에 d는 없었기 때문입니다.
반대도 가능합니다. transform 전으로 바꾸는 함수를 쓰면 됩니다.
le.inverse_transform(df['le_A'])
728x90
'머신러닝 > Preprocessing' 카테고리의 다른 글
| Scikit-learn Pipeline으로 만들기 (1) | 2024.03.05 |
|---|---|
| Decision Tree를 이용한 Wine 데이터 분석_이진분류 (0) | 2024.03.04 |
| Decision Tree를 이용한 Wine 데이터 분석_데이터 처리 (1) | 2024.03.01 |
| Decision Tree를 이용한 Wine 데이터 분석_데이터 확인 (1) | 2024.02.29 |
| Scaling (2) | 2024.02.28 |



