이번 시간에는 머신러닝에서 자주 사용하는 Scaler, Scalilng이라고도 부르는 모듈에 대해 공부해보겠습니다. 우선 강의에 나오지는 않지만 이 scaling을 왜 쓰는지, 어디에 쓰는지를 알아보고 싶어 직접 찾아보았습니다.
머신러닝, 회귀 등 모델링을 수행할 때 스케일링(scaling)은 중요한 과정 입니다. 스케일링은 범위를 재정의하는 것을 의미합니다. 여기서, 표준화(standardization)는 스케일링 방법 중 하나이며 우리는 이것이 언제 필요한지는 모른채 무작정 표준화를 수행하는 것이 대부분이라고 합니다. 강의를 통해 공부하기에 앞서, 다른집 블로그를 통해 어떻게, 왜, 언제 스케일링를 수행하는지 알아보겠습니다.
1. 왜 스케일링을 수행하는가
데이터를 보면 모든 열들 즉, 변수들은 각자 다른 단위를 가지고 있습니다. 예를 들어, 키(height)와 몸무게(weight) 변수가 있다고 하면 단위는 각각 (cm, kg)이며 관찰한 표본이 성인이라고 가정할 때 범위는 (150-190cm), (40-100kg) 정도로 다른 단위와 범위를 가지게 됩니다. 이러한 단위 차이는 몇몇 회귀 모형이나 머신러닝 기법에서 문제를 일으킬 수 있습니다.
거리 기반의 모델링(distance based model)을 수행할 때 상대적으로 범위가 넓은 몸무게 변수가 거리 계산을 하는 과정에서 더 많은 기여를 하게 되어 더 중요한 변수 or 영향력이 높은 변수로 인식될 수 있습니다. 따라서, 이러한 문제를 방지하기위한 방법 중 하나로 범위를 재정의하는 스케일링를 수행합니다.
2. 언제 스케일링을 수행하는가
위에서 언급했던 거리-기반 모델링을 할 때, 표준화는 넓은 범위의 값을 가지는 변수가 거리 측도를 지배하는 상황을 방지하기 위해 수행되어야 합니다. 하지만, 이는 거리-기반 모델링을 수행할 때 표준화를 사용해야하는 이유이며, 각 적용하고자 하는 모델링 방법에 따라 이유는 다르지만, 보통 모델에 동일한 기여를 하게끔 만들어 주는 것이 목적입니다.
1. 주성분 분석(PCA)
주성분 분석에서 높은 분산/ 넓은 범위를 가지는 변수는 낮은 분산을 가지는 변수보다 주성분에서 큰 회귀계수를 가지게 됩니다. 이는 즉, 중요하지 않은 변수도 범위가 넓으면 주성분에서 중요한 변수로 간주된다는 것인데요. 이는 모델링을 수행할 때 가장 치명적입니다.
2. 군집(clustering)
군집분석은 거리-기반 알고리즘으로 거리 측도(ex. 유클리디안, 맨하튼.. )를 이용하여 관측값 사이에서 유사성을 찾아 군집을 형성합니다. 따라서, 넓은 범위를 가지는 변수는 군집에서 더 큰 영향력을 가지게 됩니다.
3. k-최근접 이웃(knn)
k-최근접 이웃은 거리-기반 알고리즘으로 새로운 관측값의 주변에 있는 k개의 이웃(데이터)를 이용하여 유사성 측도에 기반해 관측값을 분류합니다. 따라서, 유사성 측도에 모든 변수가 동일하게 기여할 수 있도록 스케일링을 수행해야합니다.
4. 서포트벡터머신(SVM)
서포트벡터 머신은 서포트벡터와 분류기(hyperplane) 사이 거리인 마진(margin)을 최대로 만들어주는 분류기를 찾는 알고리즘입니다. 따라서, 큰 값을 가지는 변수가 거리 계산을 할 때 영향력을 많이 미치게 됩니다.
5. 회귀
예측을 위한 회귀 모델링이 목적이라면 표준화를 수행할 필요가 없지만, 변수의 중요도나 다른 회귀계수들과 비교를 하는 것이 목적이라면 표준화를 수행하여야 합니다.
6. 릿지-라쏘
릿지-라쏘 모형은 회귀계수에 벌점을 가하는 방법으로 다중공선성과 과적합을 해결하기 위해 사용됩니다. 회귀계수의 크기를 벌점으로 사용하기 때문에 상대적으로 큰 분산을 가지는 변수가 회귀계수가 클 것이고 그 회귀계수를 벌점으로 사용하게 되면 작은 분산을 가지는 변수들보다 회귀계수를 더 축소시켜 최종적인 회귀계수는 작아지게 될 것입니다.
정리하면 릿지, 라쏘는 회귀계수가 단위에 영향을 미치기 때문에 표준화를 꼭 수행해야합니다.
3. 스케일링이 필요하지 않은 경우
로지스틱 회귀나 트리 기반 모델인 의사결정나무, 랜덤 포레스트 , 그래디언트 부스팅은 변수의 크기에 민감하지 않으므로 표준화를 수행해줄 필요가 없습니다.
1, 2의 출처 : https://syj9700.tistory.com/56
왜, 언제 스케일링(standardization, min-max)를 수행해야 할까 ?
머신러닝, 회귀 등 모델링을 수행할 때 스케일링(scaling)은 중요한 과정 중 하나임을 우리는 알고 있다. 스케일링은 범위를 재정의하는 것을 의미한다. 여기서, 표준화는 스케일링 방법 중 하나이
syj9700.tistory.com
이제 강의 내용을 통해 스케일링의 종류와 어떻게 코드로 수행하는지 살펴보겠습니다.
4. 어떻게 스케일링을 수행하는가
4-1. min-max scaling
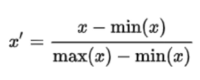
분자의 역할은 minimum을 0으로 만든 것, 분모의 역할은 크기를 1로 바꾼 것입니다. 이렇게 크기가 1이고 최솟값이 0인 scaling이 가능합니다. 분자에서 min을 0으로 만들고, 분모에서 max-min의 크기를 1인 상태로 scaling 하는 것입니다.
임의의 데이터를 만들어보겠습니다.
df = pd.DataFrame({
'A' : [10, 20, -10, 0, 25],
'B' : [1, 2, 3, 1, 0]
})
df

이제 fit 시킵니다.
from sklearn.preprocessing import MinMaxScaler
#이제 fit 시킵니다.
mms = MinMaxScaler()
mms.fit(df)
데이터를 확인해보겠습니다.
mms.data_max_, mms.data_min_, mms.data_range_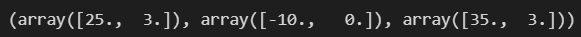
수식에 사용되는 최대값과 최소값, 범위를 fit 시켜서 가져온 것을 확인했습니다.
이제 transform 시키겠습니다.
df_mms = mms.transform(df)
df_mms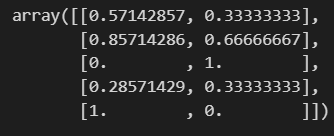
보면 최대값이 있던 자리에 1, 최소값이 있던 자리에 0이 있는 걸 확인할 수 있습니다.
여기서도 fit_transform하면 한번에 할 수 있고, inverse_transform 하면 반대로 df를 다시 얻을 수 있습니다.
mms.fit_transform(df)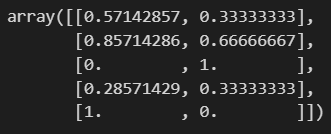
mms.inverse_transform(df_mms)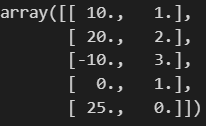
4-2. standard scaling
standard scaling은 표준 정규분포를 따라 scaling 합니다. 표준 정규분포는 아래 식을 따르는데요.
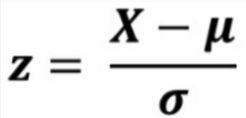
평균을 빼고 표준편차로 나눈 식입니다. 즉 정규화 시킨 것입니다. 위 식을 보면 평균을 빼고 표준편차로 나누어주므로 즉, 평균을 0으로 두고 표준편차를 1로 만드는 것입니다.
from sklearn.preprocessing import StandardScaler
ss = StandardScaler()
ss.fit(df)
standard scaler를 하기위해 분모의 표준편차와 분자의 평균이 필요하므로, 이를 잘 가져왔는지 확인해보겠습니다.
ss.mean_, ss.scale_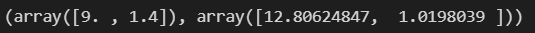
df_ss = ss.transform(df)
df_ss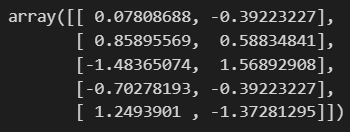
ss.fit_transform(df)
ss.inverse_transform(df_ss)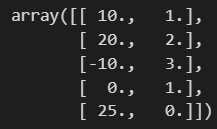
4-3. robust scaling
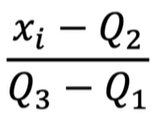
X에서 무엇을 뺀 값을 분자로 둔다는 것은 무엇을 기준으로 0을 만든다는 의미입니다.
분모는 범위므로 3분위부터 1분위를 뺀 50%를 1로 만들겠다는 뜻입니다.
분모인 Q2 즉 median 중간지점을 0으로 하겠다는 겁니다. standard는 표준이 0인데 robust는 median을 0으로 둡니다.
df = pd.DataFrame({
'A' : [-0.1, 0., 0.1, 0.2, 0.3, 0.4, 1.0, 1.1, 5.0],
})
df
df를 새로 만들었으니, 이제 위에 했던 걸 다시 불러와 복습하면서 robust scaler를 학습해보겠습니다.
from sklearn.preprocessing import MinMaxScaler, StandardScaler, RobustScaler
mms = MinMaxScaler()
ss = StandardScaler()
rs = RobustScaler()
df를 복사해서 새로운 변수를 만들겠습니다. 절대 df에 영향을 주면 안되므로 얕은복사를 합니다.
df_scaler = df.copy()
df_scaler['MinMax'] = mms.fit_transform(df)
df_scaler['Standard'] = ss.fit_transform(df)
df_scaler['Robust'] = rs.fit_transform(df)df_scaler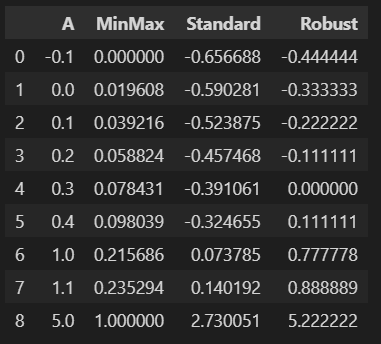
데이터를 보면 0이 되는 값이 모이고... 그런데 알기 어렵네요. 이해를 돕기위해 그래프를 그려보겠습니다.
import seaborn as sns
import matplotlib.pyplot as plt
sns.set_theme(style='whitegrid') #이쁜 디자인을 갖고옵니다.
plt.figure(figsize=(16,6))
sns.boxplot(data=df_scaler, orient='h') #수평바로 그려보겠습니다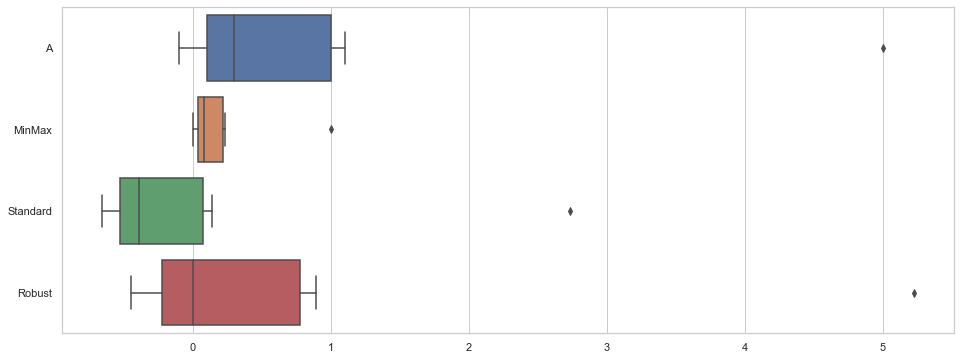
원래 원본 데이터에서 outlier가 존재했던 겁니다. df를 보면 5가 떨어져있는 데이터입니다. 따라서 각 scaler의 특징이 더 잘 보이는데요,
1. minmaxscaler는 minimum=0, maximum=1인데 outlier가 쓸데없는 데이터라면, 이로 인해 나머지 데이터가 다 찌부러지는 절망적인 결과가 나옵니다. 즉 outlier의 영향을 받아 이상해질 수 있다는 단점이 있는거죠.
2. standard scaler라고 다르지 않습니다. 평균을 0으로 두기 때문에 매우 이상한 데이터 하나로 인해 평균값이 움직이면서 결과에 영향을 미칠 수 있습니다.
3. 그러나 robust scaler를 보면 median은 outlier의 영향을 거의 받지 않습니다. median이 0이 되기 때문이죠. 그리고 3분위부터 1분위까지의 길이를 1로 두고, outlier는 outlier대로 멀리 떨어져놓습니다.
'머신러닝 > Preprocessing' 카테고리의 다른 글
| Scikit-learn Pipeline으로 만들기 (1) | 2024.03.05 |
|---|---|
| Decision Tree를 이용한 Wine 데이터 분석_이진분류 (0) | 2024.03.04 |
| Decision Tree를 이용한 Wine 데이터 분석_데이터 처리 (1) | 2024.03.01 |
| Decision Tree를 이용한 Wine 데이터 분석_데이터 확인 (1) | 2024.02.29 |
| Label encoder (1) | 2024.02.27 |



