2. 머신러닝
2-1. 머신러닝을 위한 구조 짜기
이제 진짜 머신러닝을 할 차례입니다. 생존자 예측을 위해 간단히 구조를 확인해보겠습니다.
titanic.info()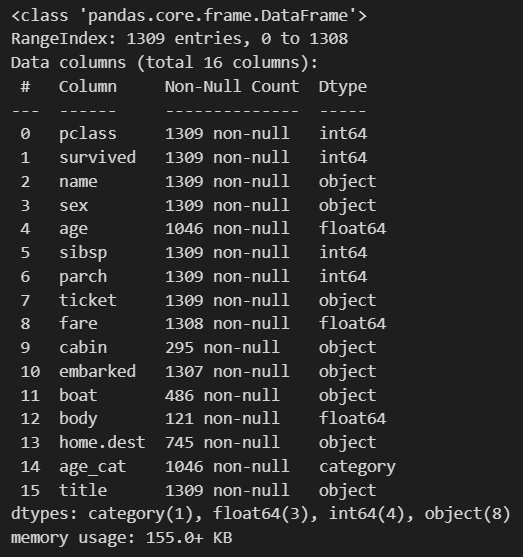
pclass, sex, age, fare, sibsp(부모형제), parch(자녀) 이런걸 볼 예정입니다
우선 머신러닝을 하기 위해서는 column들이 숫자여야 하는데 보면, sex가 object로 되어있는 걸 확인할 수 있습니다.
머신러닝을 쓰기 위해서 성별을 숫자로 바꾸는 작업이 필요합니다.
이럴 때 Label Encode를 사용하면 편리합니다.
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder() #Label encoder를 instanciation 시키고,
le.fit(titanic['sex']) #fit을 시킵니다. 무엇을? 타이타닉 승객의 성별을.
이제 LabelEncoder에 titanic['sex']가 들어있습니다. 확인해보겠습니다.
le.classes_

네 여기에는 female과 male이 있다고 알려주네요.
fit까지 했으니까 gender라는 column을 만들어주겠습니다.
le의 transform을 통해 0,1,2,...로 labeling 시켜주겠습니다.
titanic['gender'] = le.transform(titanic['sex'])
titanic.head()
info()를 다시 보겠습니다.
titanic.info()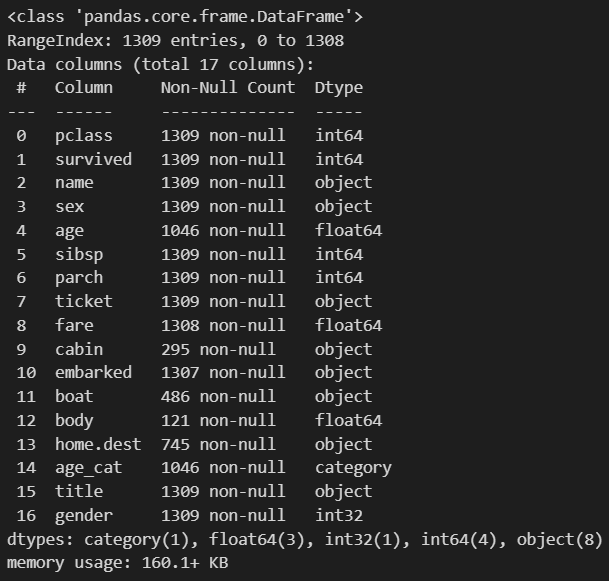
1309개의 데이터가 있어야 하는데 사용해야할 컬럼들 중 age, fare에서 결측치가 있는 걸 확인할 수 있습니다.
이렇게 결측치가 있는 행은 그냥 버리도록 하겠습니다.
titanic = titanic[titanic['age'].notnull()]
titanic = titanic[titanic['fare'].notnull()]
titanic.info()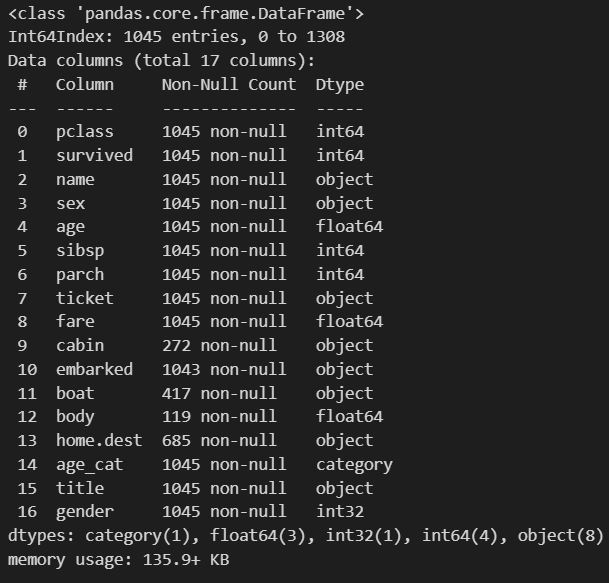
이러면 1045개로 데이터가 줄어들지만 결측치는 사라집니다.
corr() 함수를 통해 상관관계를 확인해보겠습니다. 생존율에 얼마나 영향을 미치는지 알 수 있는 함수를 사용할겁니다.
correlation_matrix = titanic.corr().round(1)
correlation_matrix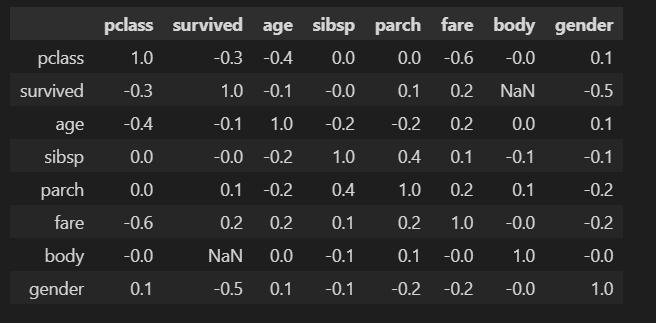
survived 열만 보겠습니다. (-)는 음의 상관관계를 나타내는 걸 나타내므로 pclass가 낮을수록 생존율이 높았으니 (-)가 나오는게 맞습니다.
0은 상관관계가 거의 안보인다라고 보면 됩니다.
이를 heatmap으로 보겠습니다.
sns.heatmap(data=correlation_matrix, annot=True, cmap='bwr')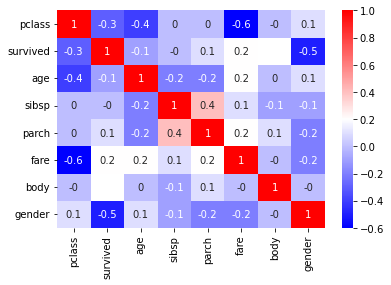
이제 앞서서 iris에서 배운걸 적용해서 특성을 선택하고 데이터를 나눠보겠습니다.
2-2. 데이터 나누고 학습/예측
이전 iris 시간에 배운 train_test_split 모듈을 활용해 학습데이터와 예측데이터를 나누겠습니다. 기억해야 할 것은 데이터를 나누는 이유가 과적합을 방지하기 위한 것이라는 겁니다.
from sklearn.model_selection import train_test_split
X = titanic[['pclass', 'age', 'sibsp', 'parch', 'fare', 'gender']]
y = titanic['survived']
X_train, X_test, y_train, y_test = train_test_split(X, y,
test_size=0.2,
random_state=13)
train 시키겠습니다. accuracy score도 같이 불러오겠습니다.
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
dt = DecisionTreeClassifier(max_depth=4, random_state=13)
dt.fit(X_train, y_train)
예측해보겠습니다.
pred = dt.predict(X_test)
print(accuracy_score(y_test, pred))
76%의 성능을 가진 상태입니다.
이제 디카프리오는 정말 살 수 없었나를 확인해보겠습니다.
2-3. 디카프리오 생존율 예측하기
디카프리오라는 새로운 array를 특정지어야 합니다.
import numpy as np
# [['pclass', 'age', 'sibsp', 'parch'#자녀, 'fare', 'gender']]
dicaprio = np.array([[3, 18, 0, 0, 5, 1]])
#이제 dicaprio를 특정지은 상황입니다.
print('Dicaprio : ',dt.predict_proba(dicaprio))
결과가 두 개가 나왔는데 이는 생존하지 못할 확률, 생존할 확률이므로 결과적으로는 [0, 1]을 씌워줘야 생존율이 나옵니다.
print('Dicaprio : ',dt.predict_proba(dicaprio)[0, 1])
16.7%의 생존율을 보입니다. random성이 있기 때문에 대략 20%를 보이는 것을 알 수 있습니다.
#winslet의 데이터도 살펴보겠습니다.
winslet = np.array([[1, 16, 1, 1, 100, 0]])
print('Winslet : ', dt.predict_proba(winslet)[0, 1])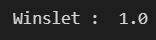
100%의 생존율을 보입니다... 영화는 머신러닝에 맞는 결과를 보였던 것 같습니다.
*. 새로배운 모듈/함수 목록
sklearn.preprocessing LabelEncoder
pd.corr()
sns.heatmap()
'머신러닝' 카테고리의 다른 글
| grid search cv의 cv값이랑 kfold의 n값은 같은 걸까? (0) | 2024.05.22 |
|---|---|
| kNN (0) | 2024.05.22 |
| 타이타닉 생존자 예측_생존율 관련 요소 (0) | 2024.02.23 |
| Decision Tree를 사용한 Iris 분류_데이터 나누기 (0) | 2024.02.23 |
| Decision Tree를 사용한 Iris 분류_과적합 (0) | 2024.02.22 |


