precision과 recall을 강제로 조정하는것은 강제로 threshold를 조정하는 것인데, 이것이 모델 성능의 향상을 말하지 않는다는 의견이 많습니다. 어차피 내가 얻은 데이터에서 작은 threshold의 움직임은 변화가 거의없고 또 threshold를 극단적으로 바꾸면 이게 의미가 없거든요. 그래도 방법은 소개해야할 것 같아서 강의에서 말하고 있습니다.
wine 데이터를 다시 불러옵니다.
import pandas as pd
red_url = 'https://raw.githubusercontent.com/PinkWink/ML_tutorial/master/dataset/winequality-red.csv'
white_url = 'https://raw.githubusercontent.com/PinkWink/ML_tutorial/master/dataset/winequality-white.csv'
red_wine = pd.read_csv(red_url, sep=';')
white_wine = pd.read_csv(white_url, sep=';')
red_wine['color'] = 1.
white_wine['color'] = 0.
wine = pd.concat([red_wine, white_wine])
wine['taste'] = [1. if grade>5 else 0. for grade in wine['quality']]
X = wine.drop(['taste', 'quality'], axis=1)
y = wine['taste']
데이터를 분리하겠습니다.
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=13)
간단한 logistic regression을 사용해보겠습니다.
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score
lr = LogisticRegression(solver='liblinear', random_state=13)
lr.fit(X_train, y_train)
y_pred_tr = lr.predict(X_train)
y_pred_test = lr.predict(X_test)
print('Train Acc.:', accuracy_score(y_train, y_pred_tr))
print('Test Acc.:', accuracy_score(y_test, y_pred_test))
Classification report
여기서 잠시 classification report에 대해 알아보겠습니다.
classification report라고,classification report(분류 보고서)는 머신러닝 분류 모델의 성능을 평가하기 위해 사용되는 지표들을 종합적으로 제공하는 보고서입니다. 일반적으로 scikit-learn 라이브러리에서 제공되는 함수를 통해 생성됩니다.
classification report에는 다음과 같은 주요 지표들이 포함됩니다:
정확도(Accuracy): 전체 예측 중에서 올바르게 분류된 샘플의 비율입니다.
정밀도(Precision): 양성 클래스로 예측된 샘플 중에서 실제로 양성 클래스인 샘플의 비율입니다. 즉, 양성 예측의 정확도를 나타냅니다.
재현율(Recall): 실제 양성 클래스 중에서 양성 클래스로 올바르게 예측된 샘플의 비율입니다. 즉, 실제 양성 샘플을 얼마나 잘 찾았는지를 나타냅니다.
F1 점수(F1 Score): 정밀도와 재현율의 조화 평균으로 계산되는 지표입니다. 두 지표가 어느 한 쪽으로 치우치지 않는 모델일수록 높은 값을 갖습니다.
지원( Support): 각 클래스의 샘플 수를 나타냅니다.
classification report는 다중 클래스 분류 문제에서 각 클래스마다 위의 지표들을 제공하며, 각 지표는 해당 클래스를 양성 클래스로 간주한 결과를 보여줍니다. 이러한 정보를 통해 모델의 분류 성능을 종합적으로 평가할 수 있습니다.
from sklearn.metrics import classification_report
print(classification_report(y_test, y_pred_test))
wine 데이터의 5등급 이상 이하로 0,1을 나누었었습니다.
1.0행의 precision은 1이라고 예측한 것 중 1일 확률
1.0행의 recall은 실제 1중에서 1을 맞춘 확률
support는 각 데이터의 개수입니다.
micro avg는 0.0일때와 1.0일때의 평균입니다.
weighted avg는 가중평균이죠. 개수를 고려해준겁니다.
Recall(sensitivity) 랑 Precision 등 계산하는 방법이었죠. 아래 그림을 통해 다시 상기해봅시다.
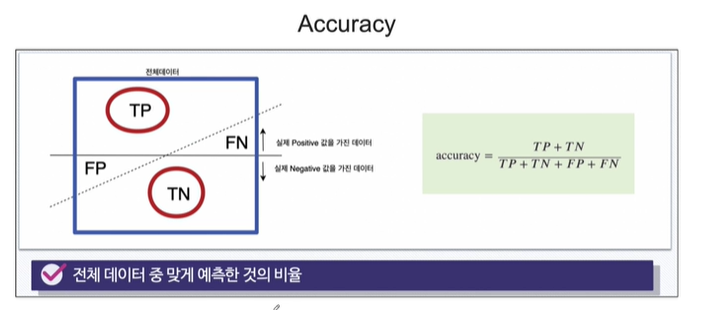


Confusion matrix
confusion_matrix() 함수는 분류 모델의 성능을 평가하기 위해 사용되는 행렬로, 실제 클래스와 예측된 클래스 간의 오차를 보여줍니다. 이 행렬은 scikit-learn 라이브러리에서 제공됩니다.
분류 모델이 예측한 결과와 실제 결과를 비교하여 생성되며, 각 클래스에 대한 예측 결과가 실제 클래스와 어떻게 관련되는지를 나타냅니다.
실제 클래스와 예측된 클래스 간의 오차를 나타내는 행렬입니다. 행렬의 각 행은 실제 클래스를 나타내고, 각 열은 예측된 클래스를 나타냅니다. 각 셀은 해당 클래스에 대한 예측 결과를 나타냅니다.
예를 들어, 이진 분류 문제의 경우 confusion_matrix() 함수는 2x2 행렬을 반환합니다. 각 셀은 다음을 나타냅니다:
- 좌상단 셀: 실제 Negative 클래스인 샘플 중에서 모델이 Negative 클래스로 예측한 샘플 수 (True Negative, TN)
- 우상단 셀: 실제 Negative 클래스인 샘플 중에서 모델이 Positive 클래스로 잘못 예측한 샘플 수 (False Positive, FP)
- 좌하단 셀: 실제 Positive 클래스인 샘플 중에서 모델이 Negative 클래스로 잘못 예측한 샘플 수 (False Negative, FN)
- 우하단 셀: 실제 Positive 클래스인 샘플 중에서 모델이 Positive 클래스로 예측한 샘플 수 (True Positive, TP)
이러한 오차 행렬을 통해 모델의 성능을 종합적으로 평가할 수 있습니다.
from sklearn.metrics import confusion_matrix
print(confusion_matrix(y_test, y_pred_test))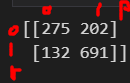
이건 전체 0중에서 275개를 0이라고 했고, 202개를 1이라고 했다는 겁니다.
전체 1중에서 691개를 1이라고 잘 맞추고, 132개를 0이라고 못맞췄다는 겁니다.
precision recall curve
import matplotlib.pyplot as plt
from sklearn.metrics import precision_recall_curve
plt.figure(figsize=(10,8))
pred = lr.predict_proba(X_test)[:,1] #1일때의 확률
precisions, recalls, thresholds = precision_recall_curve(y_test, pred)
plt.plot(thresholds, precisions[:len(thresholds)], label='precisions') #threshold에 대한 precision을 thresholds 크기만큼 그려라
plt.plot(thresholds, recalls[:len(thresholds)], label='recalls')
plt.grid()
plt.legend()
plt.show()predict_proba(X_test)[:,1]인 것은 1일때의 확률만 가져와야 하기 때문입니다.
precision을 그냥쓰면 x축 대비 precision이 커서 에러가 나므로 threshold에 대한 precision을 thresholds 크기만큼 그리라고 [:,len(thresholds)]를 붙여줘야합니다.

precisions, recalls, thresholds를 각각 보면

네 이렇게 생겼습니다.
현재 thresholds가 변해가는 것에 대해서 precision과 recall의 상황입니다.
preidct함수까지만 쓰면 threshold를 0.5로 본겁니다.
pred_proba = lr.predict_proba(X_test)
pred_proba
각 행이 1300개의 X_test 데이터들에 대한 0일확률과 1일확률입니다.
predict_proba() 함수는 주어진 입력 데이터에 대해 각 클래스에 속할 확률을 반환합니다. 이 함수는 일반적으로 다중 클래스 분류 문제에서 사용됩니다.입력 데이터가 여러 개의 샘플로 구성되어 있는 경우, 각 샘플에 대해 각 클래스에 속할 확률을 계산하여 반환합니다. 즉, 함수의 반환값은 행이 입력 데이터의 샘플 수와 같고, 열이 클래스의 수와 같은 2차원 배열이 됩니다.예를 들어, 100개의 샘플이 주어진 경우, predict_proba() 함수는 각 샘플에 대해 클래스에 속할 확률을 계산하여 100xK 크기의 배열을 반환합니다. 여기서 K는 클래스의 수를 나타냅니다.따라서 predict_proba() 함수의 행이 여러 개인 이유는 입력 데이터에 대해 각 샘플마다 클래스에 속할 확률을 계산하기 위함입니다.
여기서 결과적으로 0인지 1인지를 오른쪽 열에 붙여보겠습니다.
y_pred_test
이 친구를
y_pred_test.reshape(-1, 1)
이렇게 바꾸고 합칠겁니다.
import numpy as np
np.concatenate([pred_proba, y_pred_test.reshape(-1,1)], axis=1)
numpy.concatenate() 함수는 주어진 배열들을 하나로 합치는 함수입니다. 이 함수는 주로 배열을 연결하거나 결합할 때 사용됩니다.
axis : 배열을 결합할 축을 지정합니다. 기본값은 0이며, 이는 첫 번째 축(행)을 따라 배열들이 결합됨을 의미합니다. 1로 설정하면 두 번째 축(열)을 따라 배열들이 결합됩니다.
이렇게 할 수 있다는걸 잠깐 알아둡니다...ㅎㅎ
threshold 바꿔보기 - Binarizer
threshold를 0.5가 아닌, 사용자 지정을 받아 바꿔주면서 0과 1을 바꿔보겠습니다.
그걸 가능하게 해주는게 Binarizer입니다.
from sklearn.preprocessing import Binarizer
binarizer = Binarizer(threshold=0.6).fit(pred_proba) #주의할 점이 fit시키는 대상이 lr.pred_proba(X_test)인 pred_proba입니다.여기서 주의할 점이 fit시키는 대상이 'lr.pred_proba(X_test)'인 pred_proba입니다.
pred_proba를 fit시키는겁니다.
pred_bin = binarizer.transform(pred_proba) #pred_proba 변수를 이용해서 transform 시킵니다.
pred_binpred_proba 안에 threshold=0.5가 적용되어 있으므로 binarizer.transform 변수를 이용해서 threshold=0.6으로 변환시킵니다.

결과가 이렇게 나옵니다. 우리는 또 1일 확률이 중요하므로, [:,1]을 붙여줍니다.
pred_bin = binarizer.transform(pred_proba)[:,1]
pred_bin
극단적으로 threshold=1로 바꾸면
from sklearn.preprocessing import Binarizer
binarizer = Binarizer(threshold=1).fit(pred_proba)
pred_bin = binarizer.transform(pred_proba)[:,1]
pred_bin
이런식으로 바뀌기도 합니다.
다시 classification report를 뽑아보겠습니다.
이전에 print(classification_report(y_test, lr.predict(X_test)))와 비교하기 위해 얘도 확인해보겠습니다.
print(classification_report(y_test, lr.predict(X_test)))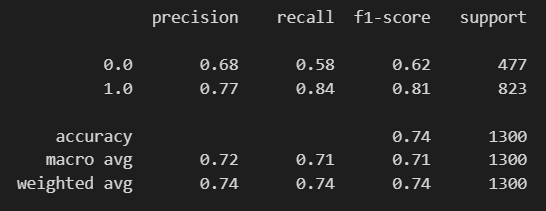
print(classification_report(y_test, pred_bin))
'머신러닝 > Logistic Regression' 카테고리의 다른 글
| Logistic Regression - PIMA 인디언 당뇨병 예측 (0) | 2024.05.07 |
|---|---|
| Logistic Regression - 실습 (0) | 2024.05.06 |
| Logistic Regression - 이론 (0) | 2024.05.06 |
| Logistic Regression - PIMA 인디언 당뇨병 예측 (0) | 2024.05.04 |



