Logistic Regression은 Linear Regression과 다르게 분류기에 사용됩니다.
악성 종양을 찾는 문제는 분류일까요 회귀일까요?
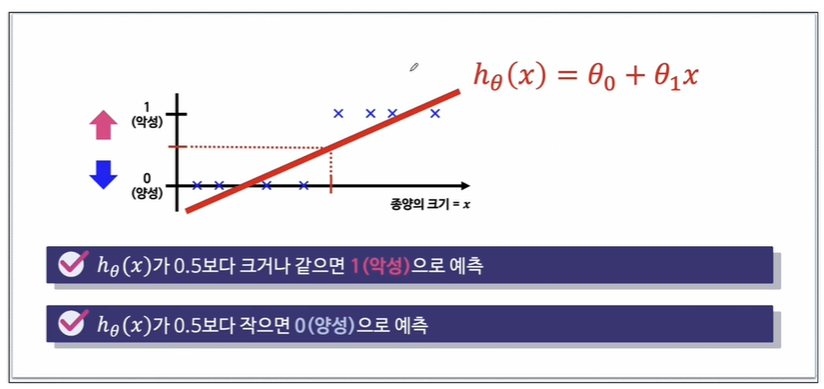
종양의 크기를 가지고 양성과 악성으로 나눈다고 한다면, linear regression이 될 것입니다.
우리가 가져가고 싶은 label은 0,1밖에 없기 때문에 직선을 그어야합니다.
0.5지점인 threshold를 두고 나누면 될 것 같습니다.
그런데 저 멀리에 데이터가 있다면 linear regression으로는 분류하기 어려울 수 있습니다.
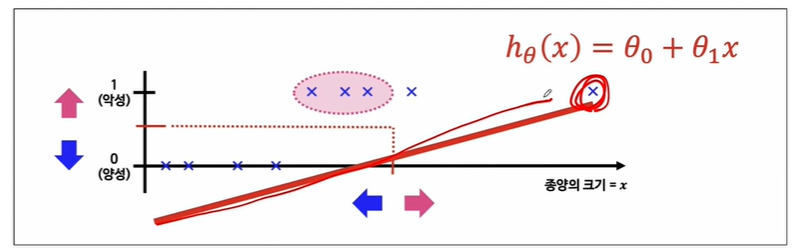
이럴 때 직선모델을 쓰는게 아니라 좀 특이한 모델을 가져옵니다.
다시 말해서, 분류 문제는 0 또는 1로 예측해야 하나 linear regression을 그대로 적용하면 예측값(h(x))는 0보다 작거나 1보다 큰 값을 가질 수 있습니다.
따라서 h(x)가 항상 0에서 1사이의 값을 갖도록 hypothesis 함수를 조정합니다

이 특이한 함수가 저번에 봤던 signoid입니다. 출력이 0과 1사이의 값을 가지도록 만드는 녀석이죠.
시그모이드에 직선을 합성시키는 겁니다.
간단히 테스트해보겠습니다.
import numpy as np
z = np.arange(-10, 10, 0.01)
g = 1 / ( 1+np.exp(-z) )여기서 잠깐 linspace와 헷갈릴 수 있는데 numpy의 linspace() 함수는 특정 구간을 쪼개어 값을 생성한다는 점에서 arange() 함수와 비슷합니다.
하지만 arange() 함수에서는 간격을 지정하고 linspace()함수에서는 구간의 개수를 지정한다는 점에서 차이가 있습니다.
python 유저답게 확인해보겠습니다.
import matplotlib.pyplot as plt
%matplotlib inline
plt.plot(z, g);
plt.grid() #grid를 넣어 0,0.5을 지나는지 보겠습니다.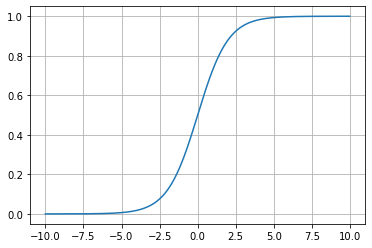
잠깐 다른얘기지만, 그래프 그리는 디테일을 잡아보겠습니다.
논문에 쓰기 좋은 그래프는 이렇게 설정힙니다.
ax = plt.gca()를 사용하고
ax.spines[].set_position()
ax.spines[].set_color()를 써서 나타내보겠습니다.
plt.figure(figsize=(12, 8))
ax = plt.gca() #gca()는 설정값을 변경할 수 있는 함수로 instanciation 시킵니다.
ax.plot(z, g)
#여기에 하나씩 지정해보겠습니다.
ax.spines['left'].set_position('zero') #left축을 0으로 옮긴다는 겁니다.
ax.spines['bottom'].set_position('center') #맨 밑축을 0이 아닌 center로 옮긴다는 겁니다.
ax.spines['right'].set_color('none')
ax.spines['top'].set_color('none')
plt.show()
이런 것들은 이제 함수로 간단하게 만들어서 사용하기도 합니다. 이런 결과도 눈에 익혀두겠습니다.
아무튼 이 signoid를 이용해서 이제 결과가 1이 될 확률을 찾을겁니다.

signoid를 그린 뒤, h(x)가 0.5보다 크거나 같으면 1(악성)으로 예측할 것이고
h(x)가 0.5보다 작으면 0(양성)으로 예측할 것입니다.
이왕 얘기가 나온거 decision boundary에 대해 얘기해볼까합니다.
Decision Boundary
저번에 iris 데이터에서 setosa, virgicolor, verginica의 scatter를 그림으로 나눌 때의 그 경계선을 decision boundary라고 합니다.
내가 그래프를 어떻게 잘라봤더니, setosa가 되고 virgicolor가 되더라 일때 그 선이 decision boundary가 되는겁니다.
이 boundary는 원으로 생길 수도 있고 cost function은 2차함수지만
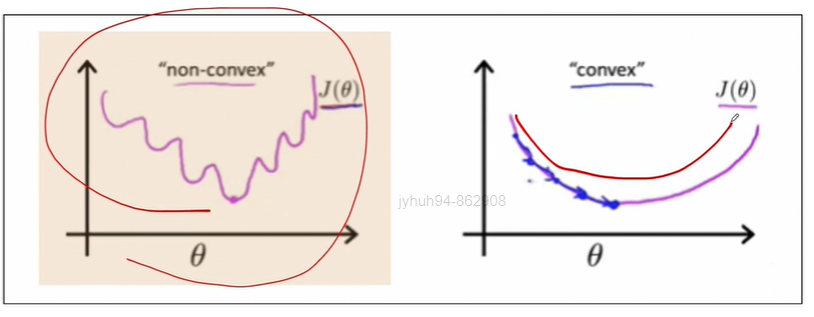
이렇게 생길수도 있습니다. linear regression에서의 cost function은 미분하면 간단해지지만,,, logistic regression에서의 cost function은 미분하기 어렵게 생겼습니다. 따라서 logistic regression에서의 cost function은 재정의됩니다.
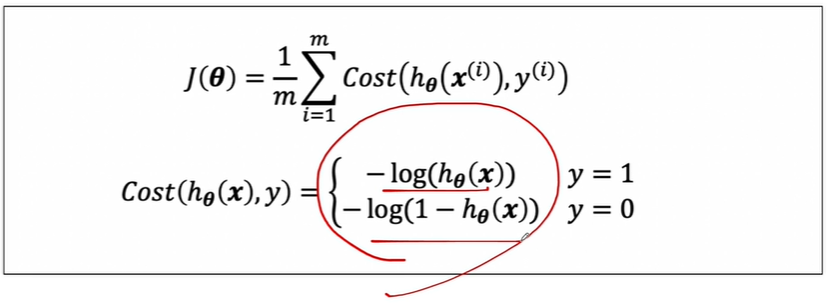
얘를 미분할 겁니다. 이걸 그리면 매끄러운 2차식이 가능해진다고 합니다.
learning 할 때 알고리즘상 학습률(Learning rate, alpha)에 따라서 cost function을 계속 미분해야 하기 때문에 어차피 미분할 필요가 있으므로,,, 우선 그래프를 그려보겠습니다.
*중요한 것은 logistisc regressioin은 "분류" 문제이고, signoid 함수에 직선함수를 넣어서 결과를 판정하는 아이입니다.
*만약 logistic regression에서 특성이 여러개라면, 여기서 반영이 됩니다.

theta2x theta3x ~~이렇게 불어나게 되는겁니다.
'머신러닝 > Logistic Regression' 카테고리의 다른 글
| Precision(정밀도)과 Recall(재현율)의 Trade off (0) | 2024.05.07 |
|---|---|
| Logistic Regression - PIMA 인디언 당뇨병 예측 (0) | 2024.05.07 |
| Logistic Regression - 실습 (0) | 2024.05.06 |
| Logistic Regression - PIMA 인디언 당뇨병 예측 (0) | 2024.05.04 |



