1. 데이터 가공 및 accuracy 확인하기
이전에 했던 와인데이터를 바탕으로 모델을 평가하기 위해 ROC 커브를 그려보겠습니다.
우선 데이터를 불러옵니다.
import pandas as pd
red_url = 'https://raw.githubusercontent.com/PinkWink/ML_tutorial/master/dataset/winequality-red.csv'
white_url = 'https://raw.githubusercontent.com/PinkWink/ML_tutorial/master/dataset/winequality-white.csv'
red_wine = pd.read_csv(red_url, sep=';')
white_wine = pd.read_csv(white_url, sep=';')
red_wine['color'] = 1.
white_wine['color'] = 0.
wine = pd.concat([red_wine, white_wine])
wine['taste'] = [1. if grade>5 else 0. for grade in wine['quality']]
wine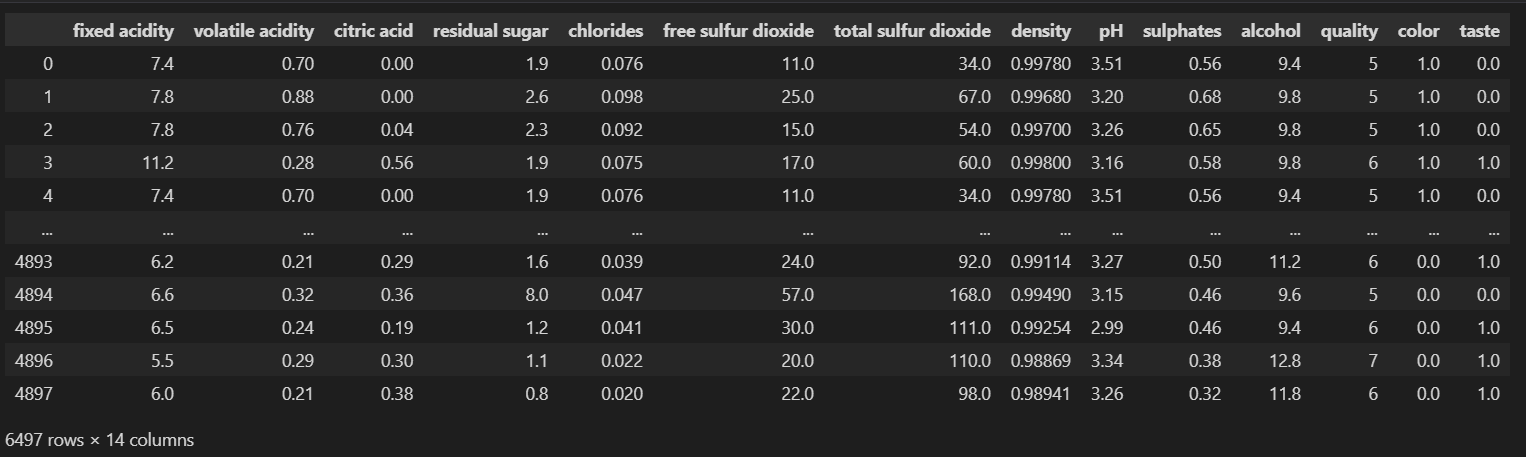
기존에 했던 머신러닝 방식과 동일하게 진행합니다.
X = wine.drop(['taste', 'quality'], axis=1)
y = wine['taste']from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=13)
wine_tree = DecisionTreeClassifier(max_depth=2, random_state=13)
wine_tree.fit(X_train, y_train)
y_pred_tr = wine_tree.predict(X_train)
y_pred_test = wine_tree.predict(X_test)
print('Train accuracy : ', accuracy_score(y_train, y_pred_tr))
print('Test accuracy : ', accuracy_score(y_test, y_pred_test))
까먹은지 오래된 것 같으니 다시 머신러닝 순서를 정리해보겠습니다.
데이터를 가공하고, 즉 X(feature), y(label)를 만들어주고, train test split합니다. 그 후 tree를 만들어 학습(fit) 시킨 뒤 train, test 모두 예측(predict)합니다.
예측된 값의 정확도를 알기위해 train, test 각각의 accuracy_score를 확인해줍니다.
from sklearn.metrics import accuracy_score, precision_score
from sklearn.metrics import recall_score, f1_score
from sklearn.metrics import roc_auc_score, roc_curve
print('Accuracy : ',accuracy_score(y_test, y_pred_test))
print('Recall : ',recall_score(y_test, y_pred_test))
print('Precision : ',precision_score(y_test, y_pred_test))
print('AUC score : ',roc_auc_score(y_test, y_pred_test))
print('F1 score : ',f1_score(y_test, y_pred_test))
2. ROC커브 그리기
import matplotlib.pyplot as plt
pred_prob = wine_tree.predict_proba(X_test)[:, 1]
pred_prob
여기서 [:,1]을 쓰는 이유에 대해서 알아보겠습니다.
#[:,1]을 쓰는 이유
wine_tree.predict_proba(X_test)
#0일 확률과 1일확률이 같이 나오므로 모든 행의 1번째 값(1일확률)만 취득하기 위해서이다.
[:,1]을 하지않으면 0일 확률과 1일 확률이 같이 나옵니다. 그런데 ROC커브를 그리기 위해 필요한 fpr과 tpr의 경우 1일 확률에 관련된 인자이므로, 우리는 1일 확률만 알면 됩니다. 따라서 모든 행렬에 대해 0이 아닌 1번째 값만 가져오기 위해 [:,1]을 붙이게 됩니다.
roc_curve(y_test, pred_prob)
roc_curve를 쓰면 이와같이 3개의 array가 나오는데, 이는 각각 fpr, tpr, thresholds를 의미합니다. 그리고 5개의 커브 점을 나타냅니다.
따라서 인자를 지정해주기위해 이와같이 코드를 짭니다.
fpr, tpr, thresholds = roc_curve(y_test, pred_prob)
fpr
tpr
thresholds
plt.figure(figsize=(10,8))
plt.plot(fpr, tpr)
plt.grid()
plt.show()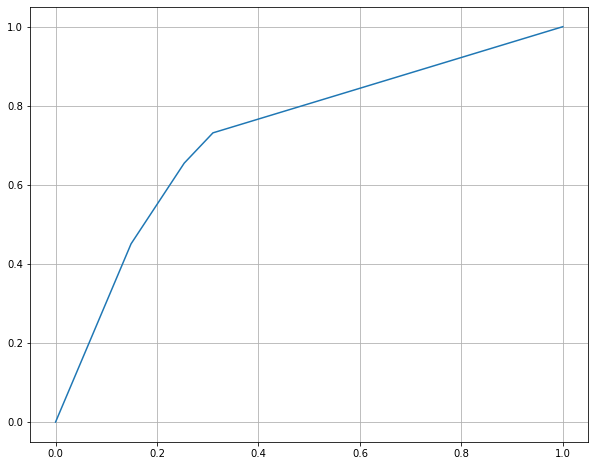
점 자체가 5쌍이기 때문에 부드러운 곡선은 아니네요.
ROC curve라고 불리우는 그림은 보통 0,0부터 1,1까지의 선이 있으므로, 이 선을 하나 추가하고 싶은 경우 이와같이 합니다.
plt.figure(figsize=(10,8))
plt.plot([0,1],[0,1]) #(0,0)부터 (1,1)까지 선을 추가한다
plt.plot(fpr, tpr)
plt.grid()
plt.show()
plt.figure(figsize=(10,8))
plt.plot([0,1],[0,1], 'c', ls='dashed') #색상과 line style을 dashed로 보조선 역할을 하는걸 표현한다
plt.plot(fpr, tpr, 'r')
plt.grid()
plt.show()
보조선이라는 것을 표현하기 위해 위와같이 표현하는 사람들도 많다고 합니다.
'머신러닝 > Model Evaluation' 카테고리의 다른 글
| Python Box plot (0) | 2024.04.27 |
|---|---|
| Python으로 다양한 함수 나타내기 (+다항함수, 지수함수, 시그모이드, 벡터 3Dscatter) (0) | 2024.04.25 |
| 모델평가_ROC와 AUC 개념 (0) | 2024.03.12 |
| 모델평가_모델평가란? (0) | 2024.03.11 |



