우리가 지금까지 배운 것들은 머신러닝을 하기위한 것들이었습니다.

우리는 데이터를 가공하고 변환하는 작업을 하고 모델을 만들고 학습하고 예측합니다.
이 모델을 평가하고 이 과정을 계속 돕니다. 모델을 평가하고 다시 가공하고 다시 학습하고 예측하고 평가하고 다시 새로운 파라미터를 손보고 다시 학습하고 예측하는 이러한 반복작업을 합니다.
1. 회귀모델
우리는 보통 크게 회귀모델과 분류모델로 나눕니다. 먼저 회귀모델에 대해 말해보겠습니다.

회귀모델들은 실제값과 선형그래프 사이의 에러치를 가지고 계산하는 모델이라 회귀모델의 평가는 간단한 편입니다.
회귀모델의 경우 내가 가지고 있는 데이터를 어떤 직선이나 곡선으로 만들어두고 이 값들을 예측해서 사용하는겁니다. 따라서 회귀모델의 예측값은 연속된 변수값들입니다. 선 위에 있으니까요. 예를 들어서 3년차 직장인의 연봉을 예측할 때 1,2,3년차로 올라가면서 예측하고, 몸무게와 나이를 가지고 키를 예측하는 경우도 연속된 값으로 예측 결과가 나타나고 이러한 경우 회귀모델을 씁니다.
2. 분류모델

그러나 분류모델은 평가항목이 좀 많습니다. 강아지인지 고양이인지 구분하기, iris 품종 맞추기 같이 몇개의 종류에서 값을 찾아내야합니다.
이러한 분류모델에서 정확도를 계산하기 위해 accuracy_score를 사용했었지만, 이것 말고도 많은 것들이 있습니다.
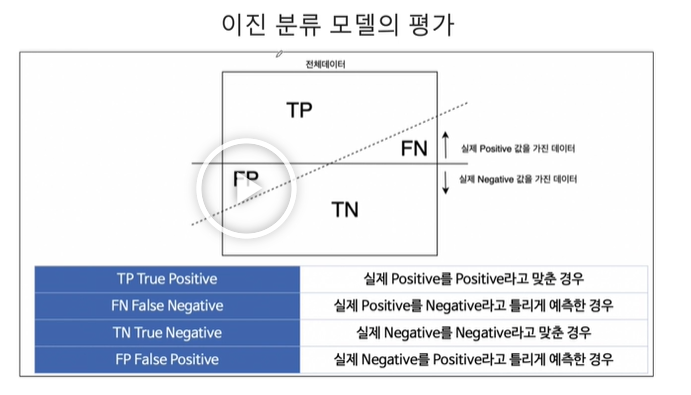
이진 분류(0과 1을 맞추는 분류로 wine 데이터일때 맛이 있다와 없다고 나누었던 것)는 그림에서 큰 네모가 전체 데이터라면 이 네모를 반을 잘라서 실제 1의 값을 가진 데이터가 위에 있고, 실제 0의 값을 가진 데이터가 아래 있습니다. 그 중에서 1을 1로 맞추면 TP(True positive), 1을 0이라고해서 못맞추면 FN(False negative), 0을 0이라고 맞추면 TN(True negative), 0을 1이라고 긍정하면 FP(False positive)라고 합니다.
결국 이진분류는 참값이 0아니면 1인것이므로 예측결과는 4가지 경우의 수가 나옵니다. 우리는 지금까지 답을 맞췄다 틀렸다라고 2가지 경우의 답만 생각했는데 그게 아니었던 겁니다.

쉽게 외우기 위해 실제값은 True/False로 나누고 예측값은 Positive/Negative로 나눈다는 것을 알 수 있습니다.
재밌는 짤이 있네요.

1종 오류는 가설이 아닌데 맞다고 오해한 경우를 말합니다. 1종 오류는 FP네요.
3. accuracy
분류모델의 평가항목 중에 accuracy가 있었습니다. 이는 전체 데이터중에 몇개를 맞췄냐는 겁니다. 따라서 아래와 같은 수식을 쓸 수 있습니다. 4가지 중에 2가지가 해당되는거죠.
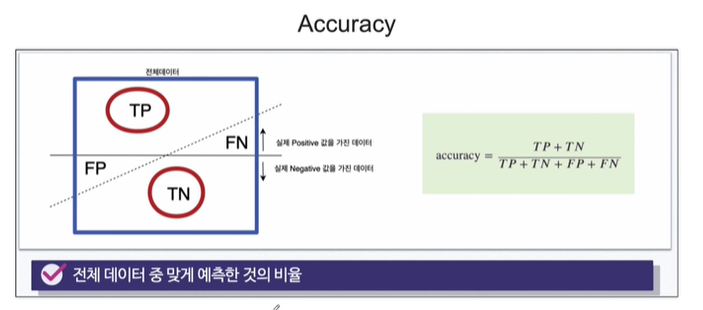
우리는 이미 accuracy_score()라는 함수를 통해 이를 맞춰왔습니다.
4. precision(정밀도)
1이라고 예측한 것 중에서 실제 1인것을 말합니다. 즉 양성이라고 예측한 것 중에서 실제 양성의 비율을 말합니다. 아래 파란 영역에서 빨간 동그라미 부분을 말합니다. 즉, 0도 있고 1도 있는데 내 모델이 1이라고 대답한 것들 중에서 진짜 1인것의 비율입니다. 이 정밀도는 모델이 1이라고 말한것에 대해서만 의미가 있습니다. 정밀도를 높이려면 매우 확실할때만 1이라고 말하는 모델을 만들어야합니다.

스팸메일이 대표적인 예입니다. 내 메일함에 스팸메일이 조금 있어도 괜찮습니다. 그런데 중요한 메일을 스팸이라고 오해하면 안됩니다. 스팸이라고 예측한 것 중에서 실제 스팸이 아닌 메일이 있으면 곤란하기 때문입니다.
5. RECALL(재현율)
TPR이라고하는 True positive ratio라고도 부릅니다. 실제 1인 데이터 중에서 1이라고 맞춘 비율입니다.

어떤 병원에서 암을 진단했다고 치겠습니다. 암인지 모르는 환자들을 데려와서 암이라고 진단을 내렸습니다. 암 환자가 아닌데 암이라고 진단을 내렸다고 쳤다면? 괜찮습니다. 그런데 암 환자인데 암이 아니라고 진단을 내린 경우, 큰일이 납니다. 이럴때 중요한게 recall입니다. 놓쳐서는 안되는 일을 신경써야 할 때 봐야하는 지표입니다.
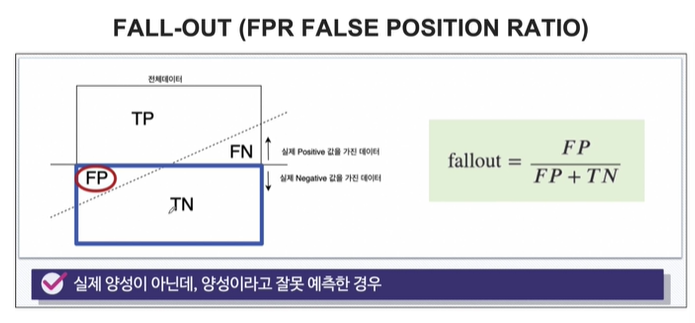
6. FALL-OUT()
FPR, False position ration라고도 부릅니다. 실제 1이 아닌데, 1이라고 잘못 예측한 비율을 말합니다.
7. Threshold
분류 모델은 그 결과가 속할 비율 (확률)을 반환합니다. 타이타닉 데이터 머신러닝 시 윈슬릿은 100%, 디카프리오는 20%의 확률로 생존했었습니다. 그 때 predict probability라는 함수에서 확률 결과를 반환해줬었습니다. 이 확률 결과는 0에서 1 사이의 숫자를 반환했었는데요, 우리가 predict probability를 쓰지 않고 그냥 predict함수를 썼다면, 1아니면 0이라고 반환했을 겁니다. 이는 predict 함수는 predict probability가 0.5를 기준으로 이보다 크면 1, 작으면 0이라고 나타내기 때문입니다. 이 때 우리는 0.5를 threshold라고 부릅니다.
이 threshold를 바꿔가면서 모델 평가지표들을 관찰해보겠습니다.
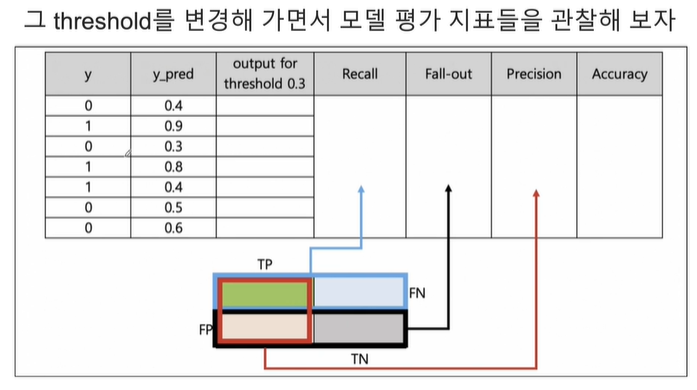
이 threshold를 바꿔가면서 recall, fall-out, precision, accuracy를 확인해보겠습니다.
우선 도표에 나온 y는 실제 y값이고, y_pred는 확률값으로, X를 통해 1이라고 대답할 확률을 말합니다. 1이 될 확률입니다.
1. threshold = 0.3
y_pred가 0.3보다 크거나 같으면 1인겁니다.

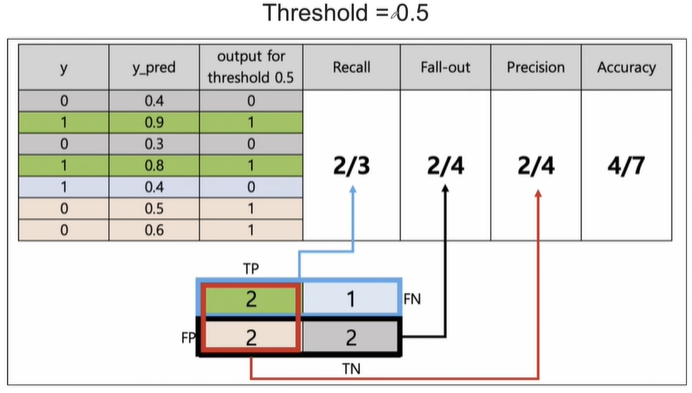
여기서 y_pred가 모두다 0.3보다 크거나 같아서 전부 1이라고 추측했습니다. TP FN FP TN의 갯수를 적은 결과를 이와같이 표로 나타나고, 이를 통해 모델 평가지표를 구할 수 있습니다. Recall은 실제 1중에서 1이라고 맞춘 확률로, 100%를 나타내네요. Fall-out은 실제 0중에서 몇개를 1이라고 틀렸냐, 전부 틀려서 100%입니다. Precision은 내가 1이라고 예측한 것들 중에서 실제 1인 확률로 7개중 3개를 맞췄습니다. Acccuracy는 맞춘 확률로 7개중에서 3개 맞춰서 3/7입니다.
2. threshold = 0.4
y_pred가 0.4보다 크거나 같으면 1인겁니다.

여기서 y_pred가 1개 빼고 0.4보다 크거나 같아서 6개를 1이라고이라고 추측했습니다. TP FN FP TN의 갯수를 적은 결과를 이와같이 표로 나타나고, 이를 통해 모델 평가지표를 구할 수 있습니다. Recall은 실제 1중에서 1이라고 맞춘 확률로, 100%를 나타내네요. Fall-out은 실제 0중에서 몇개를 1이라고 틀렸냐, 전부 하나 0 맞춰서 3/4입니다. Precision은 내가 1이라고 예측한 것들 중에서 실제 1인 확률로 맞춘 6개중 3개를 맞췄습니다. Acccuracy는 맞춘 확률로 7개중에서 4개 맞춰서 3/7입니다.
3. threshold = 0.5
y_pred가 0.5보다 크거나 같으면 1인겁니다.
4. threshold = 0.6
y_pred가 0.6보다 크거나 같으면 1인겁니다.

5. threshold = 0.8
y_pred가 0.8보다 크거나 같으면 1인겁니다.

6. threshold = 0.9
y_pred가 0.9보다 크거나 같으면 1인겁니다.

여기서 주의깊게 볼 점인 precision이 100%라는 겁니다. precision이 높아지기 위해서는 굉장히 보수적으로 1을 평가하면 됩니다. 즉 threshold가 0.9일 때 precision이 매우 높게 나옵니다. 반대인 recall은 높을수록 극단적으로 말하면 그냥 다 1이라고 말하는 겁니다.
7. 정리
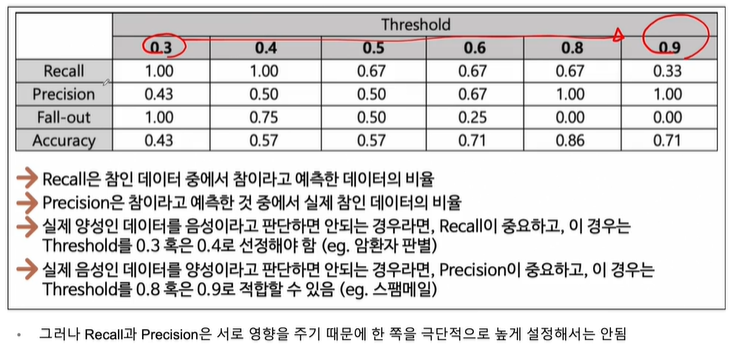
0.3부터 0.9로 threshold가 변해갈 때 모델평가지표인 recall, precision, fall-out, accuracy를 확인해봤습니다.
Recall : 실제 1중에서 몇개를 1이라고 예측했는가
Precisioin : 내가 1이라고 예측한것 중에서 진짜 1이 몇개있는가
따라서 Recall과 precision은 서로 영향을 줍니다.
Precision가 Recall이 다 중요한데 이걸 각각 보지않고, 한번에 볼 방법이 없을까?
8. F1-Score
F score는 beta라는 인자를 더한것분에 곱한것으로, 여기서 beta를 1로두면 F1-score를 말합니다. F1을 조화평균이라고 부릅니다.
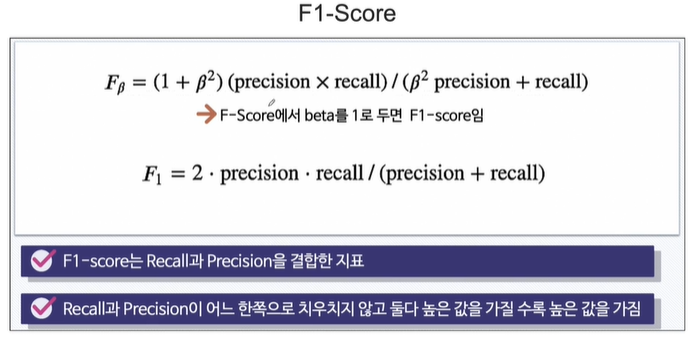
F1-score는 recall과 precision을 결합한 지표고, recall과 precision이 어느 한 쪽으로 치 우치지 않고 둘다 높은 값을 가질 수록 높은 값을 가집니다.

F1 score가 가장 높은 0.8일때가 가장 좋다고 보면 됩니다.
'머신러닝 > Model Evaluation' 카테고리의 다른 글
| Python Box plot (0) | 2024.04.27 |
|---|---|
| Python으로 다양한 함수 나타내기 (+다항함수, 지수함수, 시그모이드, 벡터 3Dscatter) (0) | 2024.04.25 |
| 모델평가_ROC 커브 그리기 (0) | 2024.04.02 |
| 모델평가_ROC와 AUC 개념 (0) | 2024.03.12 |



