이번에는 random forest 모델을 통해 머신러닝을 시켜보겠습니다.
random forest는 sklearn의 ensenble(앙상블)에서 가져올 수 있습니다.
이 random forest에도 여러 옵션이 있는데 바로 GridSearchCV로 나누어보겠습니다.
random forest는 decision tree가 많이 결합된 것이기 때문에 max_depth가 필요합니다. n_estimators는 decision tree를 몇그루 쓸 것인가에 해당합니다.
min sample leaf는 tree의 맨 끝에 들어오는걸 leaf라고 하는데 이 leaf에 데이터가 몇개 모이게 할 것인가입니다. decision tree의 맨 하단을 leaf라고합니다.
min sample split은 leaf 바로 윗단에서 분할 데이터를 몇개로 할 것인가를 의미합니다.
min sample leaf와 min sample split은 큰 영향을 주지는 않지만 이런 parameter가 있다는 것만 기억하시면 됩니다.
from sklearn.model_selection import GridSearchCV
from sklearn.ensemble import RandomForestClassifier
params = {
'max_depth' : [6, 8, 10],
'n_estimators' : [50, 100, 200],
'min_samples_leaf' : [8, 12],
'min_samples_split' : [8, 12]
}rf_clf = RandomForestClassifier(random_state=13, n_jobs=-1)
#n_jobs는 cpu core를 몇개나 써서 동시에 학습시킬 것인지인데, -1을 주면 모든 core를 다쓰라는 뜻입니다.
grid_cv = GridSearchCV(estimator=rf_clf, param_grid=params, cv=5, n_jobs=-1)
grid_cv.fit(X_train, y_train)n_jobs는 cpu core를 몇개나 써서 동시에 학습시킬 것인지인데, -1을 주면 모든 core를 다쓰라는 뜻입니다.

잘 돌아간것을 확인했습니다.
이번에도 grid_cv에서 cv_results_를 dataframe화 시켜서 df를 가져옵니다.
cv_results_df = pd.DataFrame(grid_cv_2.cv_results_)
cv_results_df.columns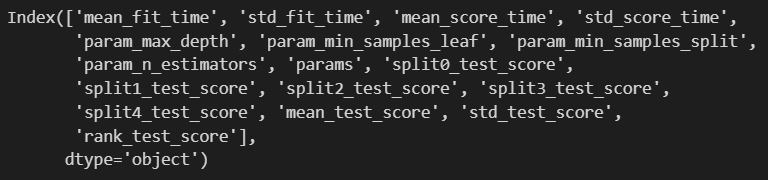
저 params를 쓰면 이런 column의 결과가 나오는군요.
데이터프레임을 확인해보겠습니다.
cv_results_df
column이 많으니 보고싶은 컬럼만 추리겠습니다.
target_col = ['rank_test_score', 'mean_test_score', 'param_n_estimators', 'param_max_depth']
cv_results_df[target_col].sort_values('rank_test_score')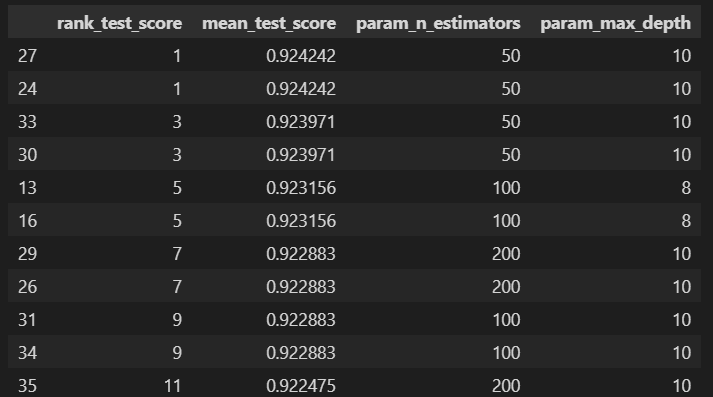
공동1위 공동3위가 있네요. 나무가 많다고 좋은게 아닙니다. test_score는 train 데이터의 validation score입니다. 모델성능이 아닙니다. 아까 decision tree에서는 mean_test_score가 90%가 안넘었는데, random forest를 쓰면 90%가 넘어갈 수 있다는걸 확인했습니다.
최적의 params를 출력해보겠습니다.
grid_cv_2.best_estimator_
dataframe으로 봤지만 best_score_로도 다시 볼 수 있습니다.
grid_cv_2.best_score_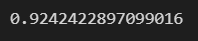
max depth=10, min samples leaf=8, min_samples_split=8, n_estimators=50, n_jobs=-1, random_state=13이군요.
이제 이 best estimator를 가지고 pred 데이터를 뽑아보겠습니다.
best_estimator를 grid_cv에서 가져온 후 이 모델로 fit 시킵니다.
rf_clf_best = grid_cv_2.best_estimator_
rf_clf_best.fit(X_train, y_train)
y_pred = rf_clf_best.predict(X_test)
accuracy_score(y_test, y_pred)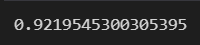
헷갈리면 안되는게 grid_cv.best_score_는 random forest에서 얻은 best parameter가 보여주는 validation score입니다.
accuracy_score는 test data에 의한 얼마나 정확한지에 대한 score입니다.
이제 데이터의 중요 특성을 추출해보겠습니다.
HAR 데이터 중요 특성 추출
feature_importances_로 영향력이 높은 column만 추려서 Series로 보려고합니다.
이를 sort시켜서 상위 20개만 보려고 합니다.
best_cols_values = rf_clf_best.feature_importances_
best_cols_values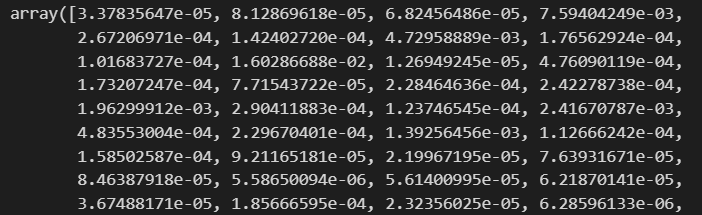
이게 뭐냐하면, feature별로 영향력입니다. 561개의 feature가 있었죠? length를 확인해보면 561개가 나오는 것을 확인할 수 있습니다.
len(best_cols_values)를 돌리면 561이 나옵니다.
이제 이걸 pd로 Series로 바꾼뒤, feature 이름을 index에 넣어주겠습니다.
best_cols = pd.Series(best_cols_values)
best_cols
각 행에 index로 X_train의 columns를 가져와주면 feature별로 매칭이 됩니다.
best_cols = pd.Series(best_cols_values, index=X_train.columns)
best_cols
이제 column이름별로 matching이 된 것을 확인했습니다. 이것만 봐도 어떤 feature는 버려도 될 것 같아보입니다.
seaborn을 통해 확인해보겠습니다.
그 전에 561개는 너무 많으니까 상위 20개만 가져와서 보겠습니다.
top_20_cols = best_cols.sort_values(ascending=False)[:20]
import seaborn as sns
plt.figure(figsize=(12, 6))
sns.barplot(x=top_20_cols, y=top_20_cols.index)
plt.show()
우리가 561개나 되는 feature를 다 쓸 것이 아니라면, 굳이 계산을 이렇게 많이 할 필요가 없습니다.
다른 쓸모없는 feature를 제거해보겠습니다.
20개 특성만 가지고 다시 성능을 확인해보겠습니다.
행은 그대로고 열이 줄어드는 것이므로 X데이터만 손보면 됩니다.
top_20_cols.index에 해당하는 컬럼만 가져옵니다.
X_train_re = X_train[top_20_cols.index]
X_test_re = X_test[top_20_cols.index]
#다시 모델을 만들 필요는 없습니다. 그런데 강의에선 다시만드네요..
rf_clf_best_re = grid_cv_2.best_estimator_
rf_clf_best_re.fit(X_train_re, y_train)
y_train.values.reshape(-1,) #강의에서는 numpy배열로 바꿔서 넣는데, 똑같습니다.
pred1_re = rf_clf_best.predict(X_test_re)
accuracy_score(y_test, pred1_re)
trade off 관계에서 모든 feature를 가지고 오래 시간이 걸려도 성능을 높일지, 적은 feature를 가지고 빠르게 돌려도 84%를 얻을지는 결정권자의 판단입니다.
'머신러닝 > 앙상블 기법' 카테고리의 다른 글
| 앙상블 기법 - Boosting algorithm - GBM, XGBoost, LGBM (0) | 2024.05.23 |
|---|---|
| 앙상블 기법 - Boosting Algorithm (0) | 2024.05.20 |
| 앙상블 기법 - HAR 데이터 Decision Tree 적용 (0) | 2024.05.10 |
| 앙상블 기법 - HAR 데이터 (0) | 2024.05.08 |
| 앙상블 기법 (0) | 2024.05.08 |


