이제 HAR 데이터를 결정나무 모델을 통해 머신러닝 시켜보겠습니다.
1. 데이터 가져오기
import pandas as pd
import matplotlib.pyplot as plt
url = 'https://raw.githubusercontent.com/PinkWink/ML_tutorial/master/dataset/HAR_dataset/features.txt'
feature_name_df = pd.read_csv(url, sep='\s+', header=None, names=['column_index', 'column_name'])
#txt도 read_csv로 읽을 수 있습니다.
#\s는 공백 한칸, \s+는 공백 여러칸입니다.
feature_name_df
t로 시작하는 데이터는 시간 영역의 데이터라는 뜻이고, f로 시작하는 데이터는 주파수 영역의 데이터라는 뜻입니다.
feature_name_df.info()
feature 이름을 보니 561개가 뜨는걸 볼 수 있습니다.
이제 feature name을 추출해보겠습니다.
feature_name = feature_name_df.iloc[:, 1].values.tolist()
feature_name
values를 안써도 되는데 왜 썼을까요? values를 사용하는 것은 DataFrame의 특정 열을 NumPy 배열로 변환하는 역할을 합니다. tolist() 메서드를 사용하면 NumPy 배열을 Python 리스트로 변환할 수 있습니다.
따라서 values.tolist()를 사용하면 DataFrame의 열을 Python 리스트로 변환할 수 있습니다. 하지만 tolist() 대신에 바로 tolist()를 사용하지 않고 values를 사용하는 이유는 코드의 가독성과 표현력 때문입니다. 두 가지 방법은 동일한 결과를 제공하지만, values.tolist()가 데이터를 배열로 변환한 후에 리스트로 변환하는 과정을 명시적으로 나타내므로 코드의 의도를 더 명확하게 전달할 수 있습니다.
이렇게 561개가 되는 feature들의 이름만 저장해보았습니다.
일단 X데이터만 가져와보겠습니다.
X_train_url = 'https://raw.githubusercontent.com/PinkWink/ML_tutorial/master/dataset/HAR_dataset/train/X_train.txt'
X_test_url = 'https://raw.githubusercontent.com/PinkWink/ML_tutorial/master/dataset/HAR_dataset/test/X_test.txt'
X_train = pd.read_csv(X_train_url, sep='\s+', header=None)
X_test = pd.read_csv(X_test_url, sep='\s+', header=None)X_train의 용량이 31MB이기 때문에 시간이 오래걸립니다.
X_train.info()column name을 지정해줍니다.
X_train.columns = feature_name
X_test.columns = feature_name
X_train.head()y데이터도 가져오겠습니다.
y_train_url = 'https://raw.githubusercontent.com/PinkWink/ML_tutorial/master/dataset/HAR_dataset/train/y_train.txt'
y_test_url = 'https://raw.githubusercontent.com/PinkWink/ML_tutorial/master/dataset/HAR_dataset/test/y_test.txt'
y_train = pd.read_csv(y_train_url, sep='\s+', header=None, names=['action'])
y_test = pd.read_csv(y_test_url, sep='\s+', header=None, names=['action'])
2. 데이터 확인하기
X_train.shape, X_test.shape, y_train.shape, y_test.shape
Xy과 7352대 2947로 나뉘어져있는것, X데이터 컬럼이 561개인것, y가 1열로 되어있는것으로 중간점검이 가능합니다.
이제 6개 각 동작의 분포를 확인해보겠습니다.
사랑하는 value_counts()를 사용하겠습니다.
y_train['action'].value_counts()
3. Decision Tree 모델을 통한 머신러닝
3번 라벨이 갯수가 적고 5,6이 갯수가 많긴 하네요... label의 균형이 맞지 않는걸 inbalalce 데이터라고 합니다.
이정도면 2배차이가 나는건 아니라서 그냥 진행하도록 하겠습니다.
이제 결정나무 모델을 적용해보겠습니다.
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
dt_clf = DecisionTreeClassifier(max_depth=4, random_state=13) #feature가 561개가 되는데 maxdepth가 2인건 너무 단순하므로 4로 하겠습니다.
dt_clf.fit(X_train, y_train)
fit() 시켜준 뒤,
pred = dt_clf.predict(X_test)
accuracy_score(y_test, pred)
80%의 높은 성능을 나타냅니다.
이제 max_depth를 다양하게 하기위해 GridSearchCV를 이용해보겠습니다.
from sklearn.model_selection import GridSearchCV
params = {
'max_depth' : [6, 8, 10, 12, 16, 20, 24] #원래 2부터 1000이나 3000까지 다양한 max_depth를 가져갑니다. 그러나 매우 초반에는 저렇게 드문드문합니다.
}
원래 2부터 1000이나 3000까지 다양한 max_depth를 가져갑니다. 그러나 매우 초반에는 저렇게 드문드문합니다.
grid_cv = GridSearchCV(dt_clf, param_grid=params,
scoring='accuracy',
cv=5, return_train_score=True)
grid_cv.fit(X_train, y_train)classifier는 dt_clf를 쓸거고, param_grid는 option인데 이 option은 params에서 지정했습니다. 기록할때 accuracy_score는 기록해달라는 것, kfold를 5로, 보통 test 데이터 score는 반환해주는데 train 데이터의 score는 반환을 잘 안해주기 때문에 return_train_score=True로 두었습니다.
이제 grid_cv를 fit시키겠습니다.

이제 알고리즘이 돕니다.
pc에 gpu코어가 있지만, grid search CV는 gpu코어를 쓰지않습니다. 이 정형 데이터를 max_depth를 6부터 24밖에 하지않았는데도 오래걸립니다.
cv=5이기 때문에 데이터를 5개로 나눠서 1개로 검증하는 법을 5번 하기 때문에 오래걸립니다.
이제 best score와 best parameter를 물어보겠습니다.
grid_cv.best_score_, grid_cv.best_params_
혼동하면 안되는 점은 best score는 모델에 대한 평가가 아닌, 검증 데이터 즉 train데이터에서 cv=5로 잡았으므로 train에서 5등분 하는 검증 데이터에 대한 평가입니다. 검증 데이터에 대한 best_score가 85.3%므로, 6개의 사람의 행동을 휴대폰만으로도 85.3%의 정확도로 잡아낸다는 뜻이죠.
max depth가 8이 나왔으니, 몇천까지 가지않아도 8근처에서 세분화해서 찾아보려고합니다. 그렇게 높은 max depth가 필요하지 않네요.
이 결과를 잔기술을 동원해서 표로 이쁘게 정리해보겠습니다.
cv_results_df = pd.DataFrame(grid_cv.cv_results_)
cv_results_df.columns
column이 꽤 많습니다. 우리가 뽑은 데이터는 param max depth와 mean test score, mean train score를 가져오겠습니다.
cv_results_df = cv_results_df[['param_max_depth', 'mean_train_score', 'mean_test_score']]
cv_results_df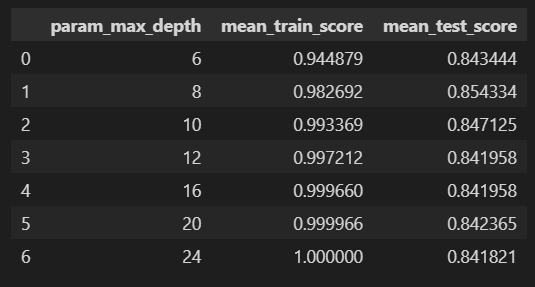
test score에서의 최고점과 train score에서의 최고점이 둘다 8이었다는걸 알 수 있습니다.
그러나 test score는 0.8대, train score에서 0.9대라 간격이 좀 있네요. 과적합일까?를 의심해야합니다.
mean_train_score는 모델이 학습 데이터에 얼마나 잘 적합되는지를 나타냅니다.
mean_test_score는 모델이 새로운 데이터에 대해 얼마나 잘 일반화되는지를 나타냅니다.
이러한 점수를 통해 모델이 학습 데이터에 과적합되었는지, 또는 일반화가 잘 되었는지 등을 평가할 수 있습니다. 보통 학습 데이터에 대한 점수가 검증 데이터에 대한 점수보다 높을 수 있습니다. 그러나 두 점수 간의 차이가 너무 크면 모델이 과적합되었다는 것을 의미할 수 있습니다.
여기까지 우리는 진짜 train 데이터에 대해서 확인한 결과입니다.
max_depth = [6, 8, 10, 12, 16, 20, 24]
for depth in max_depth:
dt_clf = DecisionTreeClassifier(max_depth=depth, random_state=13)
dt_clf.fit(X_train, y_train)
pred = dt_clf.predict(X_test)
accuracy = accuracy_score(y_test, pred)
print('Max_Depth : ', depth, ', Accuracy : ',accuracy)
cv데이터에 대해서도 그렇고, test 데이터에 대해서도 역시 max depth 8일때가 좋습니다.
아무튼 우리의 베스트 모델의 결과는 8입니다.
grid_cv에서 굳이 이렇게 for문을 돌리지않고 accuracy 결과를 가져올수도 있습니다.
best_dt_clf = grid_cv.best_estimator_
best_dt_clf
이러면 바로 max depth에 8을 나타냅니다.
best_dt_clf = grid_cv.best_estimator_
pred1 = best_dt_clf.predict(X_test)
accuracy_score(y_test, pred1)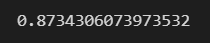
이렇게하면 최적화된 max depth에서의 accuracy를 바로 알 수 있습니다.
'머신러닝 > 앙상블 기법' 카테고리의 다른 글
| 앙상블 기법 - Boosting algorithm - GBM, XGBoost, LGBM (0) | 2024.05.23 |
|---|---|
| 앙상블 기법 - Boosting Algorithm (0) | 2024.05.20 |
| 앙상블 기법 - HAR 데이터 Random Forest (0) | 2024.05.18 |
| 앙상블 기법 - HAR 데이터 (0) | 2024.05.08 |
| 앙상블 기법 (0) | 2024.05.08 |



