cost function은 error를 표현하는 도구라고 합니다. 그 중에서도 지난시간에 우리는 MSE(mean square error)를 확인해봤습니다.
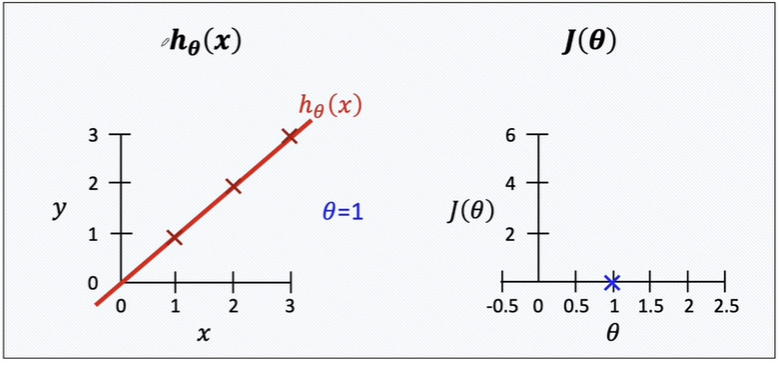
theta가 1, 즉 예측 모델이 모조리 일치했다면 cost func은 0이 될것입니다.
만약 cost func가 조금 빗나갔다면 theta가 0.5로 두어서 에러가 증가한다면?
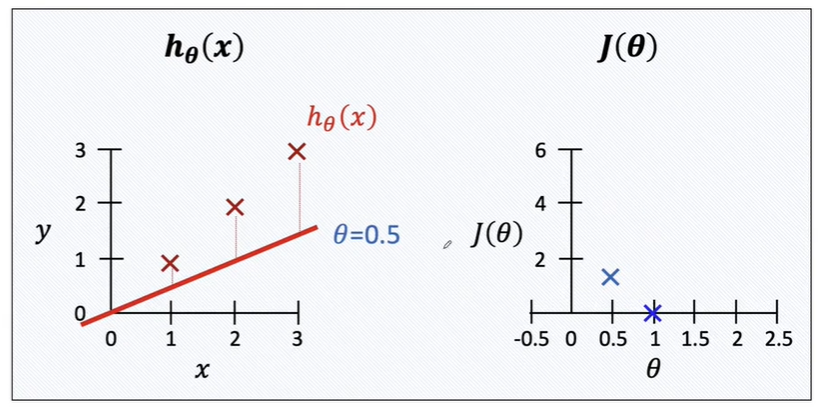
에러값이 더 커진다면?
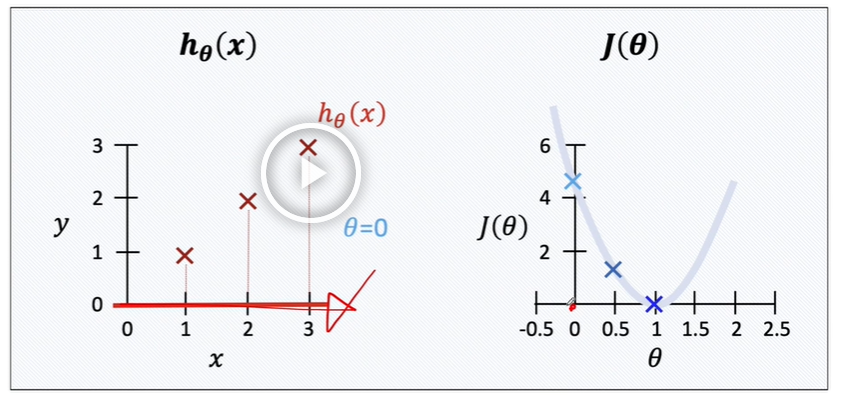
결과적으로 cost function은 theta에 따라 2차함수를 띄게 됩니다.
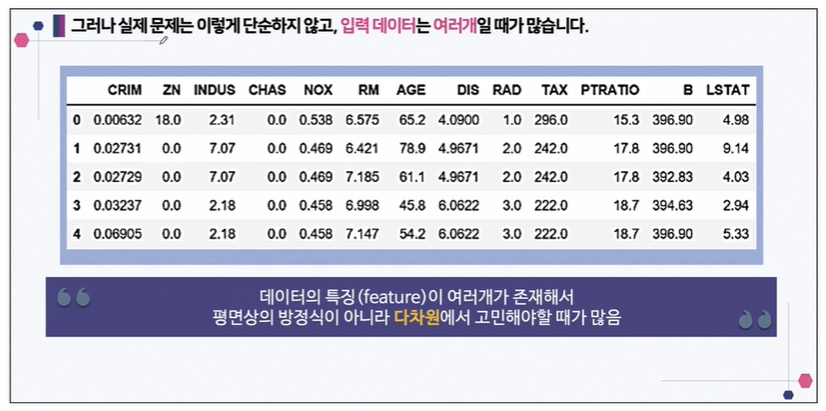
그런데 실제 데이터는 너무 복잡해서 손으로 풀기 어렵습니다.
OLS도 풀리지 않는 경우도 많습니다. OLS는 모든 데이터를 가지고 엄청 큰 행렬을 만드는 겁니다. 그리고 그 큰 행렬을 한 방에 역행렬을 구하고 transpose를 취합니다. 미분하는 것도 복잡하죠.
cost function이 만약에 아래와 같이 3d로 된 어려운 모양을 띄게되면 어떻게 할까요? 이 정도 데이터면 손으로 문제를 푸는 것은 매우 어렵습니다.
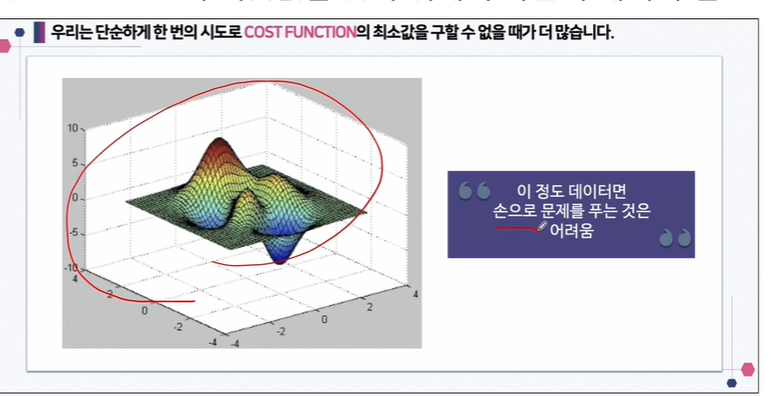
그래서 cost function의 최솟값을 구하는 방법을 다시 생각해볼 필요가 있습니다.
그 방법 중 하나가 Gradient Descent입니다.
Gradient Descent
책에서 개념설명을 위해서 사용하는 용어이고, 최근에 쓰는 용어는 아닙니다.
랜덤하게 아까의 그 2차방정식에서 임의의 점을 선택해보겠습니다.
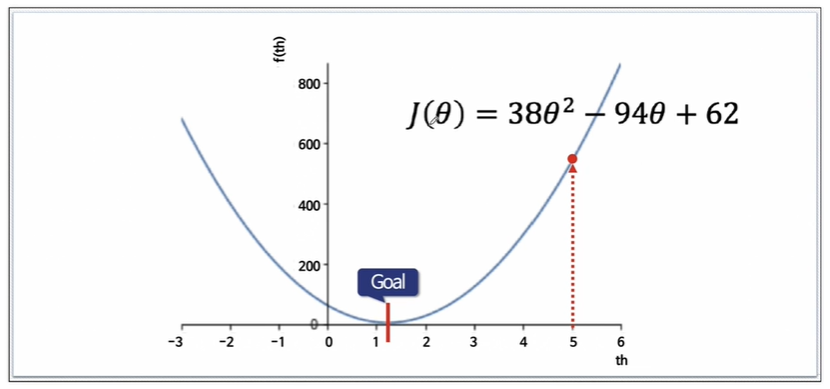
처음에는 랜덤하게 하나의 값을 정합니다.
임의의 점에서 미분(or 편미분)값을 계산해서 업데이트합니다.
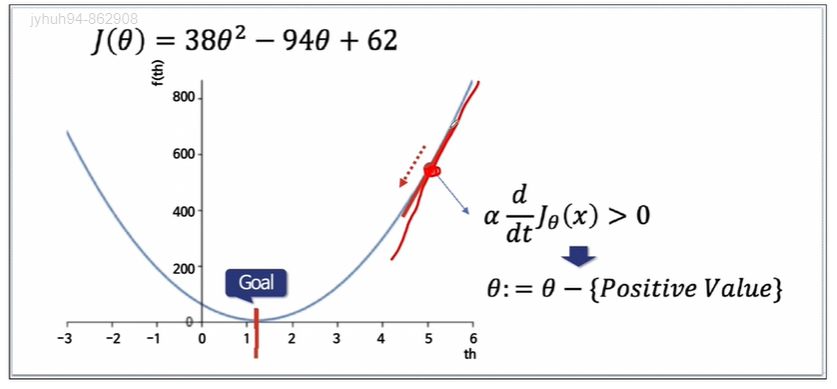
임의의 값이 목표점의 오른쪽이었다고 가정해봅시다.
그러면 미분결과는 양수가 됩니다.
따라서 그 이전 theta에다가 미분값(양수)을 뺍니다. 그러면 현재 theta는 작아집니다. 이렇게 목표점에 가까워지는겁니다.
반대로 임의의 값이 목표점의 왼쪽이었다고 가정해봅시다.
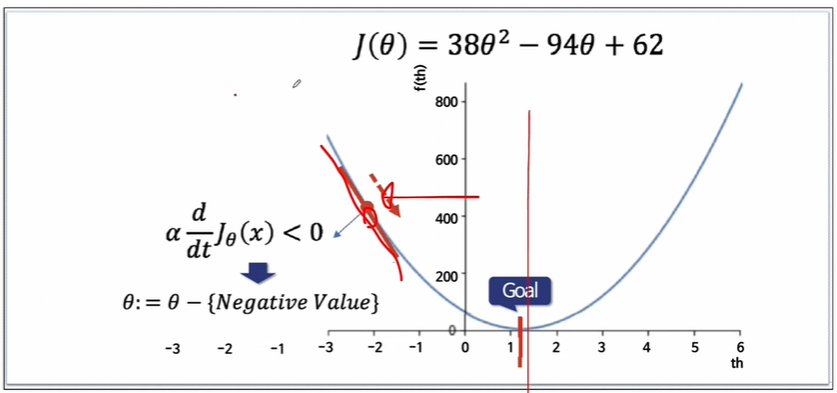
그러면 미분값이 음의값을 가집니다.
음의 값을 빼므로 더하기가 되어 오른쪽으로 움직입니다.
다 타고 내려와서 goal(목표점)에 도착하게합니다.
이것이 gradient descent입니다.
여기서 아까 알수없는값 alpha가 미분값에 곱해져있었는데, 이 alpha는 Learning Rate라고 합니다.
Learning Rate(학습률)

만약 학습률이 크다면 아래 이미지처럼 움직일 수도 있습니다.

최솟값에 도착도 못하고 같은 구간을 왔다갔다할 수도 있습니다.
따라서 적당한 값을 찾아야하는 하이퍼파라미터입니다.
우리는 feature가 정말 많이 있을 수 있습니다. multi variable linear regression 문제라고 합니다.

입력변수(feature)가 4개여도 어차피 행렬로 표현할 거라 괜찮습니다.

Gradient descent는 미분을 통해서 cost func의 최솟값을 찾는다는 매우 중요한 개념입니다.
만약 학습률이 작다면
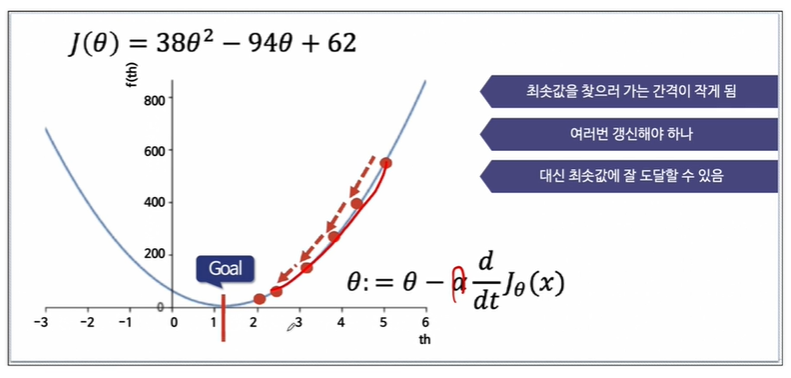
최솟값을 찾는 간격이 작지만 여러번 갱신해야하고, 대신 최솟값에 도달할 수 있습니다.
'머신러닝 > Linear Regression' 카테고리의 다른 글
| Cost function - Boston 집값 예측 (0) | 2024.05.05 |
|---|---|
| 회귀를 통해 이해하는 Cost function_1 (0) | 2024.05.03 |
| [통계] 회귀 (1) | 2024.05.03 |
| Linear Regression - OLS(최소자승법) (1) | 2024.05.02 |
| 선형 회귀(Linear Regression) - 회귀 (1) | 2024.04.28 |



