EDA 시간에 네이버 API에서 만든 함수를 들고오겠습니다.
우선 필요한 모듈을 호출합니다.
import urllib.request
import json
import datetime
def gen_search_url(api_node, search_text, start_num, disp_num):
#api_node는 book/shop/encyc인지 확인하는 것
base = "https://openapi.naver.com/v1/search"
node = "/" + api_node + ".json" #json 형태로 받고있음, naver개발자에 이렇게 하라고함
param_query = "?query=" + urllib.parse.quote(search_text)
param_start = "&start=" + str(start_num) #네이버개발자센터에서 start_num을 int형태로 준다고했음
param_disp = "&display=" + str(disp_num) #int형태므로 str()시킴
return base + node + param_query + param_start + param_dispgen_search_url이라는 함수를 만들었었는데, 이건 naver의 원래 주소의 특성을 따서 책,쇼핑,백과사전,지식인 등을 확인하고 찾는 텍스트를 입력하고, 시작지점과 표시하는 갯수를 집어넣으면 주소를 나타내게 하는 함수를 만들었었습니다.
그리고 이렇게 만들어진 url에 접속해서 Naver client Id와 secret number를 입력해 결과데이터를 가져오는 함수인 get_result_onpage를 만들었습니다.
def get_result_onpage(url):
request = urllib.request.Request(url)
request.add_header("X-Naver-Client-Id",client_id)
request.add_header("X-Naver-Client-Secret",client_secret)
#url을 불러왔으니 응답받아야함
response = urllib.request.urlopen(request)
print("[%s] Url Request Success" %datetime.datetime.now()) #현재시간
return json.loads(response.read().decode("utf-8")) #가져온게 json파일이라
이제 각자의 Naver api에서 만든 client_id와 client_secret을 들고온 후,
지식인에서 파이썬을 검색해서 1번부터 100개를 들고오라고 합니다.
client_id = ""
client_secret = ""
url = gen_search_url('kin', '파이썬', 1, 100) #kin은 지식인 검색입니다
one_result = get_result_onpage(url)
one_result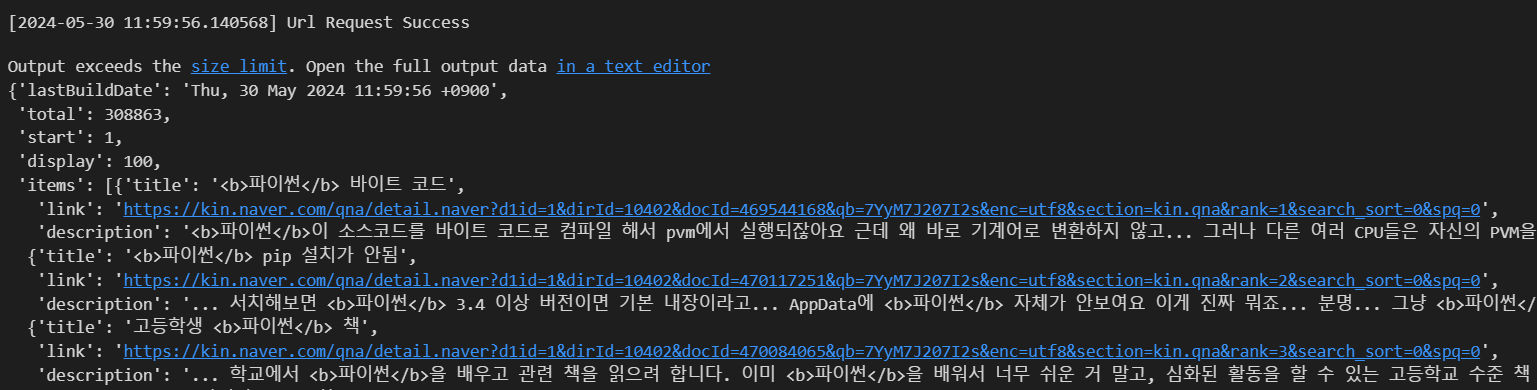
이런식으로 dict안에 또 list와 dict가 있는걸 확인할 수 있습니다.
우리가 가져오고싶은 지식인 내용은 items에 0번째(리스트므로)의 description에 있네요.
one_result['items'][0]['description']'<b>파이썬</b>이 소스코드를 바이트 코드로 컴파일 해서 pvm에서 실행되잖아요 근데 왜 바로 기계어로 변환하지 않고...
여기서 <b> 같은 태그들을 없애려고 합니다. 함수를 만들어주겠습니다.
def delete_tag(input_str):
input_str = input_str.replace("<b>","")
input_str = input_str.replace("</b>","")
return input_str
이제 items에서 0번째에서 description을 delete_tag함수를 씌운 후 결과를 뱉는 함수를 만듭니다.
def get_description(pages):
contents = []
for sentences in pages['items']:
contents.append(delete_tag(sentences['description']))
return contents
이제 함수를 one_result에 적용시켜보겠습니다.
contents = get_description(one_result)
contents
네, 리스트에 한개씩 잘 담겨있네요. 태그도 빠진걸 확인했습니다.
100개의 description만 가져왔습니다.
이제 유사도 측정을 위해 vector화 하기위한 count vectorizer, 형태소 분석을 위한 Okt를 가져와겠습니다.
list 형태로 만들어서 말뭉치까지 만들게요.
from sklearn.feature_extraction.text import CountVectorizer
from konlpy.tag import Oktt = Okt()
vectorizer = CountVectorizer(min_df=1)contents_tokens = [t.morphs(row) for row in contents]
contents_tokens[['파이썬',
'이',
'소스코드',
'를',
'바이트',
'코드',
'로',
'컴파일',
'해서',
'pvm',
'에서',
'실행',
'되잖아요',
'근데',
...
'&',
'gt',
';',
'b',
')...']]
len(contents_tokens)100
네, 100개의 문장에서 가져온게 맞네요. 이제 이걸 문장끼리 형태소단위로 띄어쓰기를 해서 list로 담겠습니다.
contents_for_vectorize = []
for content in contents_tokens:
sentence = ''
for word in content:
sentence = sentence + ' ' + word
contents_for_vectorize.append(sentence)
contents_for_vectorize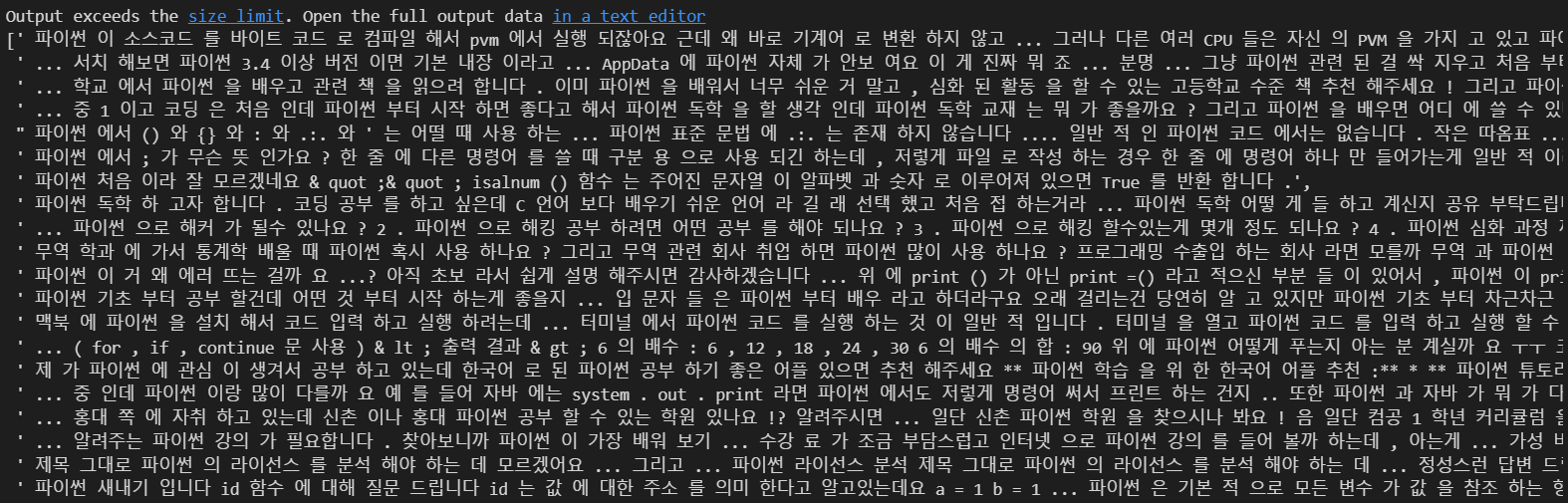
이렇게 형태소 단위로 띄워놨습니다.
이제 fit_transform 시켜놔야죠.
X = vectorizer.fit_transform(contents_for_vectorize)
X<100x1222 sparse matrix of type '<class 'numpy.int64'>'
with 2349 stored elements in Compressed Sparse Row format>
X.toarray().transpose()array([[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
...,
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0]], dtype=int64)
num_samples, num_features = X.shape
num_samples, num_features(100, 1222)
100개의 데이터(문장)이 있었고, 1222개의 vector가 만들어집니다.
이제 새로운 문장을 데려와서 형태소 분석을 하고 형태소로 띄어서 문장을 만든뒤 vectorize시켜보겠습니다.
그래야 거리를 구하고 유사도를 확인할 수 있으니까요 :)
new_post = ['파이썬을 배우는데 좋은 방법이 어떤 것인지 추천해주세요']
new_post_tokens = [t.morphs(row) for row in new_post]
new_post_tokens[['파이썬', '을', '배우는데', '좋은', '방법', '이', '어떤', '것', '인지', '추천', '해주세요']]
new_post_for_vectorize = []
for content in new_post_tokens:
sentence = ''
for word in content:
sentence = sentence + ' ' + word
new_post_for_vectorize.append(sentence)
new_post_for_vectorize[' 파이썬 을 배우는데 좋은 방법 이 어떤 것 인지 추천 해주세요']
이제 이걸 vector화 시키겠습니다.
new_post_vec = vectorizer.transform(new_post_for_vectorize)
new_post_vec.toarray()array([[0, 0, 0, ..., 0, 0, 0]], dtype=int64)
100개의 문장이다 보니까 너무 많아서 생략되네요 하하하
distance로 바꾸는걸 아까 해놨지만 한번더 코드를 작성해보겠습니다.
import scipy as sp
def dist_raw(v1, v2):
delta = v1 - v2
return sp.linalg.norm(delta.toarray())
dist = [dist_raw(each, new_post_vec) for each in X]
dist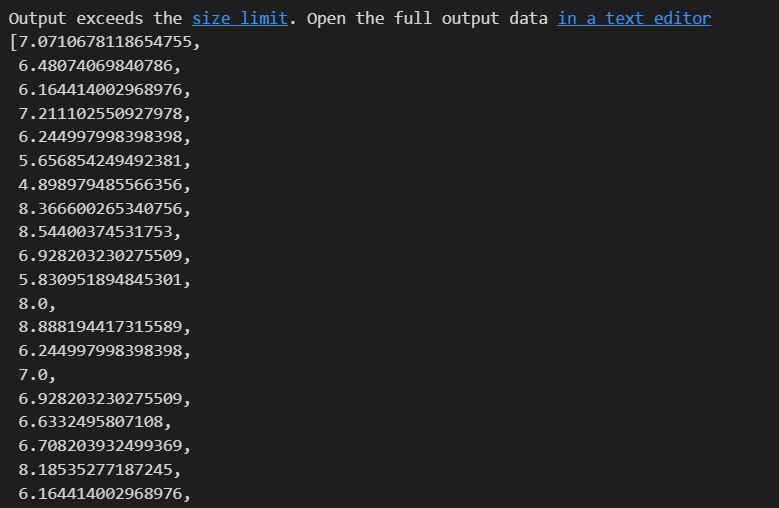
print('Best post is', dist.index(min(dist)), ', dist = ', min(dist))
print('Test post is -->', new_post)
print('Best dist post is -->', contents[dist.index(min(dist))])Best post is 6 , dist = 4.898979485566356
Test post is --> ['파이썬을 배우는데 좋은 방법이 어떤 것인지 추천해주세요']
Best dist post is --> 파이썬 처음이라 잘 모르겠네요 "" isalnum() 함수는 주어진 문자열이 알파벳과 숫자로 이루어져 있으면 True 를 반환합니다.
다른 문장도 해보겠습니다.
new_post = ['파이썬을 독학하려는데 좋은 책이 있나요']
new_post_tokens = [t.morphs(row) for row in new_post]
new_post_for_vectorize = []
for content in new_post_tokens:
sentence = ''
for word in content:
sentence = sentence + ' ' + word
new_post_for_vectorize.append(sentence)
new_post_vec = vectorizer.transform(new_post_for_vectorize)
dist = [dist_raw(each, new_post_vec) for each in X]
print('Best post is', dist.index(min(dist)), ', dist = ', min(dist))
print('Test post is -->', new_post)
print('Best dist post is -->', contents[dist.index(min(dist))])Best post is 6 , dist = 4.69041575982343
Test post is --> ['파이썬을 독학하려는데 좋은 책이 있나요']
Best dist post is --> 파이썬 처음이라 잘 모르겠네요 "" isalnum() 함수는 주어진 문자열이 알파벳과 숫자로 이루어져 있으면 True 를 반환합니다.
똑같은 문장이 나왔네요? 그래도 dist가 다르니까 일단 믿어봅니다..
new_post = ['파이썬으로 인공지능을 어떻게 공부하나요']
new_post_tokens = [t.morphs(row) for row in new_post]
new_post_for_vectorize = []
for content in new_post_tokens:
sentence = ''
for word in content:
sentence = sentence + ' ' + word
new_post_for_vectorize.append(sentence)
new_post_vec = vectorizer.transform(new_post_for_vectorize)
dist = [dist_raw(each, new_post_vec) for each in X]
print('Best post is', dist.index(min(dist)), ', dist = ', min(dist))
print('Test post is -->', new_post)
print('Best dist post is -->', contents[dist.index(min(dist))])Best post is 28 , dist = 4.69041575982343
Test post is --> ['파이썬으로 인공지능을 어떻게 공부하나요']
Best dist post is --> 파이썬 코들에서 하고있는데 너무 불친절하게 나와서요 어떻게 해야하는지 풀이와 정답좀 알려주세요,,, (아래가 문제입니다) .을 기준으로 나눠서 마지막 부분과 .을 합치면 되겠습니다.
dist가 똑같은게 좀 소름돋긴 하지만... 문장이 짧아서 그렇다고 믿고ㅠㅠ 그래도 문장이 다르니까 믿어봅니다...
new_post = ['기계과에서 파이썬 공부하면 좋나요']
new_post_tokens = [t.morphs(row) for row in new_post]
new_post_for_vectorize = []
for content in new_post_tokens:
sentence = ''
for word in content:
sentence = sentence + ' ' + word
new_post_for_vectorize.append(sentence)
new_post_vec = vectorizer.transform(new_post_for_vectorize)
dist = [dist_raw(each, new_post_vec) for each in X]
print('Best post is', dist.index(min(dist)), ', dist = ', min(dist))
print('Test post is -->', new_post)
print('Best dist post is -->', contents[dist.index(min(dist))])Best post is 22 , dist = 4.58257569495584
Test post is --> ['기계과에서 파이썬 공부하면 좋나요']
Best dist post is --> 파이썬에서 증가값이 머에요? 파이썬 고유의 용어는 아니고요 말그대로 점점 커지는 값을 의미해요 예를들어 1 4 5 8 10 33 이런게 증가값이죠
일부러 질문에 있는 글자를 따왔는데 해당 글자를 가져오진 않네요 흠... 믿을 만한지는 잘 모르겠습니다 하하하...
'머신러닝 > NLP(자연어처리, Natural language processing)' 카테고리의 다른 글
| 자연어 처리 - 문장의 유사도 측정 (0) | 2024.05.30 |
|---|---|
| 자연어 처리 - 나이브베이즈 분류기 (0) | 2024.05.30 |
| 자연어 처리 - 육아휴직관련법안 분석 (0) | 2024.05.28 |
| 자연어 처리 - 워드클라우드 (0) | 2024.05.28 |
| 자연어 처리 - 형태소 분석 (0) | 2024.05.27 |


